
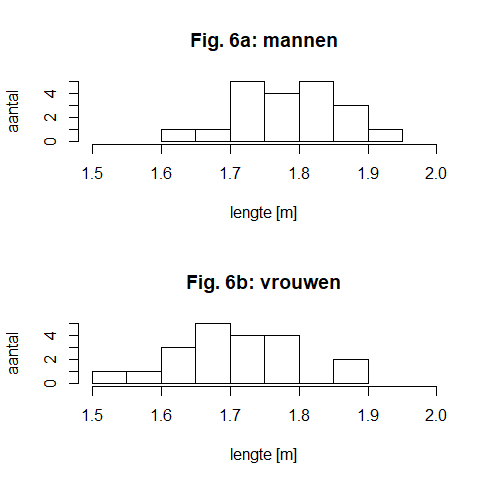
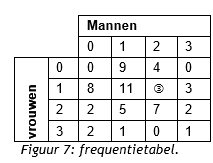
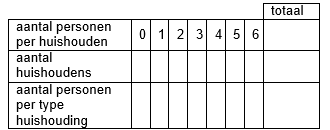
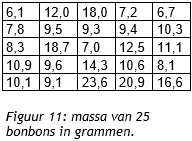
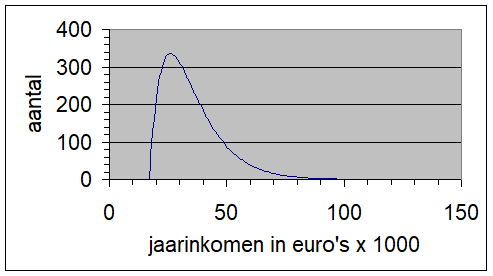






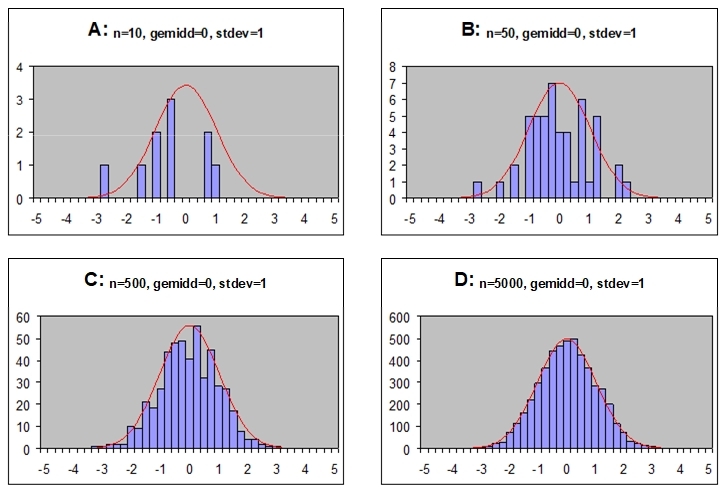
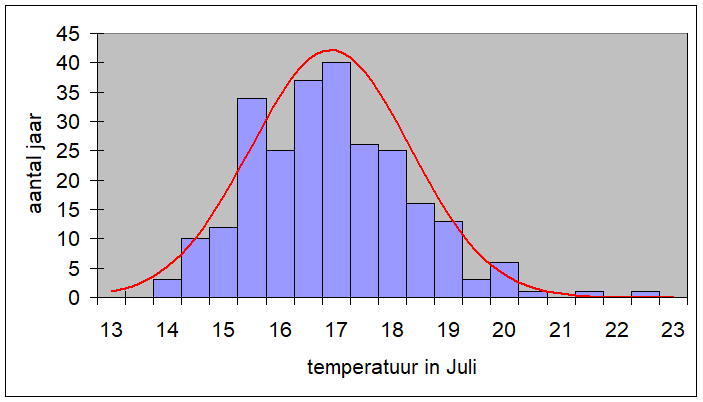
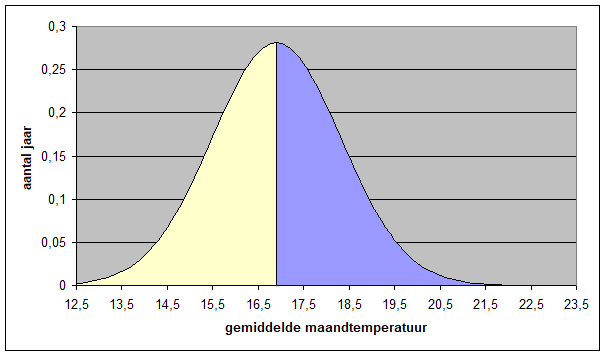
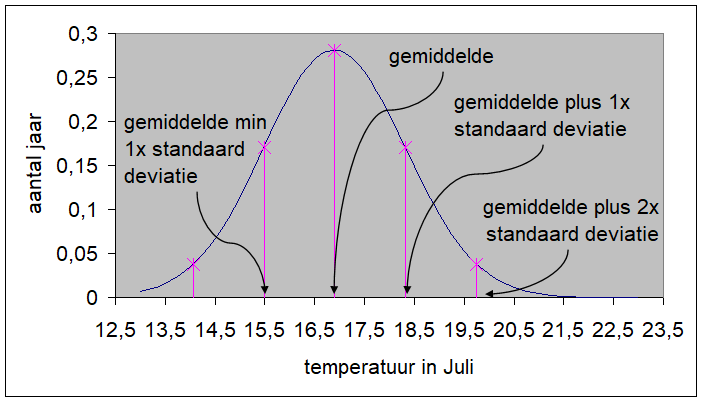
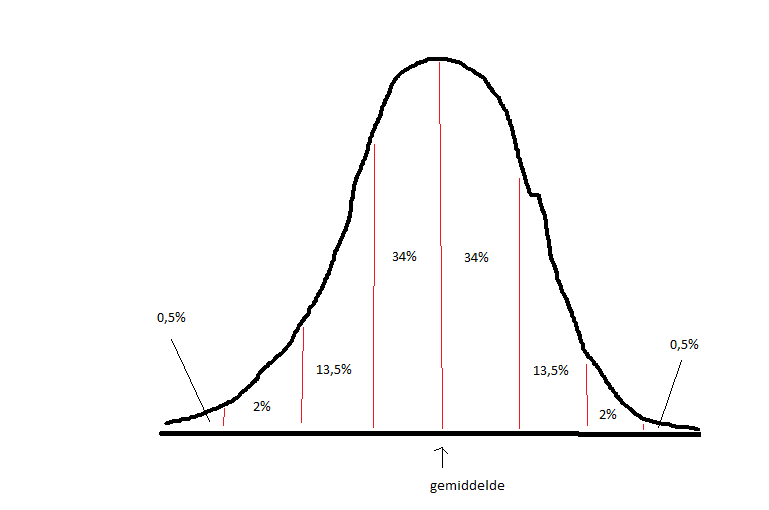
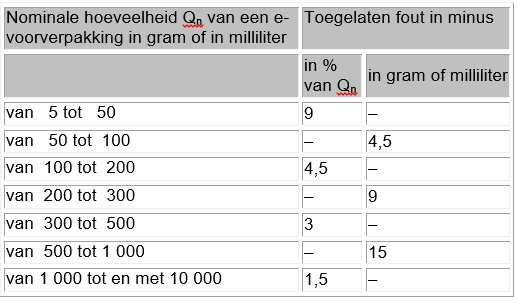


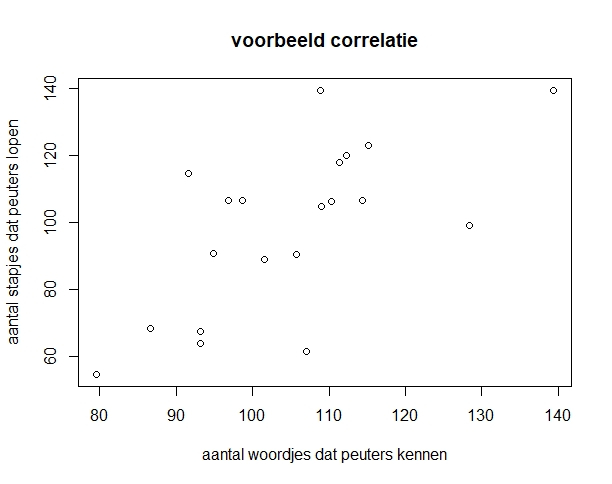
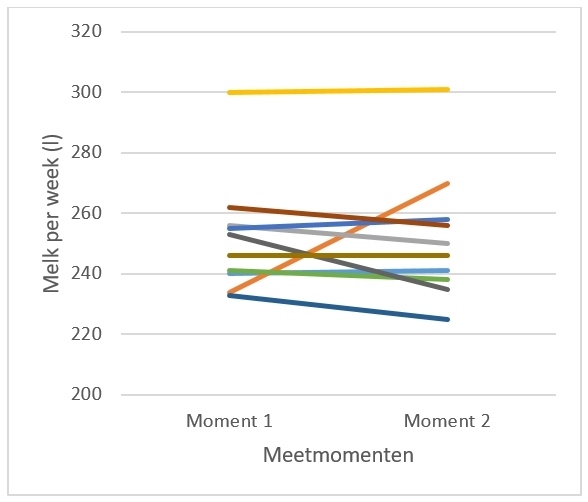
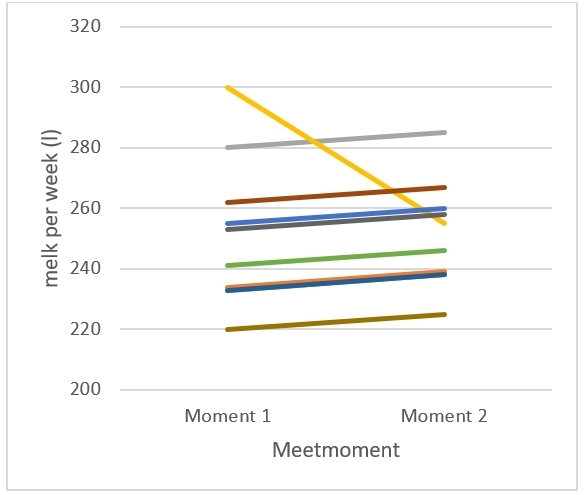

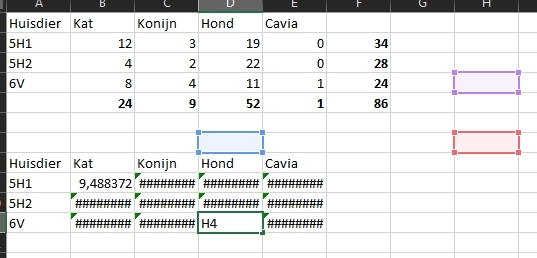
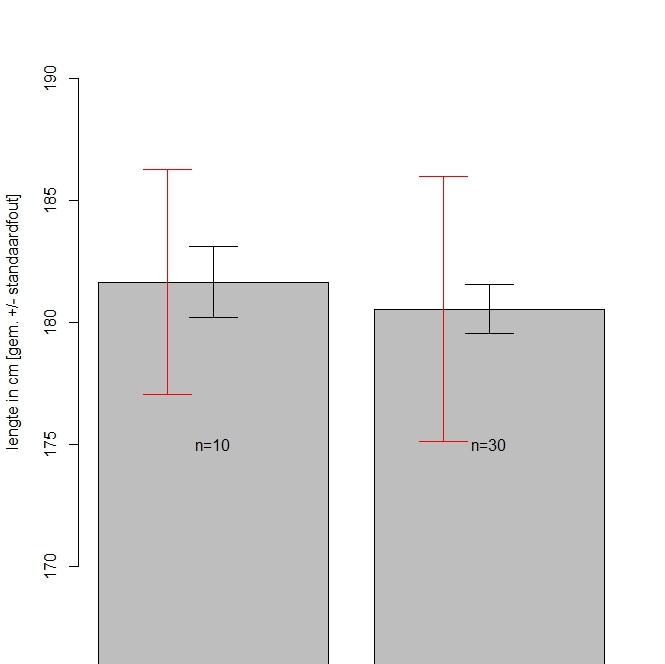

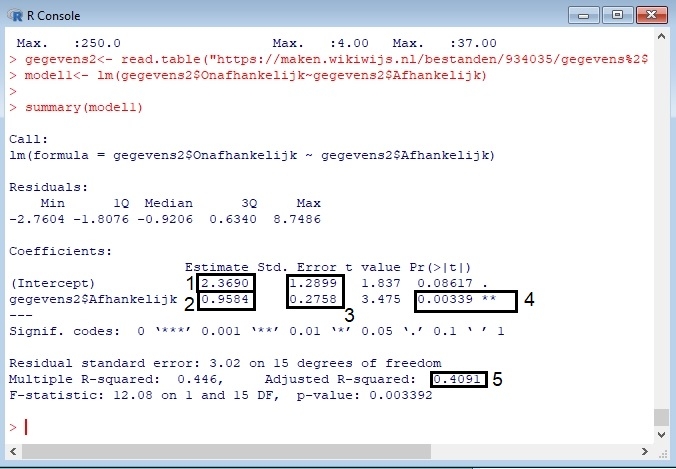




Het arrangement NLT Statistiek voor onderzoeken en PWS is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 10-10-2022 09:50:36
- Licentie
-



Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding-GelijkDelen 4.0 Internationale licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding en publicatie onder dezelfde licentie vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding-GelijkDelen 4.0 Internationale licentie.
Deze module is een bewerking van de oude versie van de NLT module 'Maak het verschil' versie 1 uit 2008. Dit is gedaan onder de Creative Commons licentie van deze module (Creative Commons Naamsvermelding-Niet-commercieel-Gelijk delen 3.0 Nederland Licentie).
Hoofdstuk 1 is geschreven door M.R. Jonker
Hoofdstuk 2 is afkomstig uit de module Maak het verschil
Hoofdstuk 3 is afkomstig uit de module Maak het verschil
Hoofdstuk 4 is afkomstig uit de module Maak het verschil
Hoofdstuk 5 is afkomstig uit de module Maak het verschil
Hoofdstuk 6-11 zijn geschreven door M.R. Jonker
Feedback op deze lesstof is gekregen van Dennis Groenveld, Suzanne Wensink en Casper Albers en vele leerlingen die ermee gewerkt hebben.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 4 uur 0 minuten