


 Bekijk het filmpje.
Bekijk het filmpje.
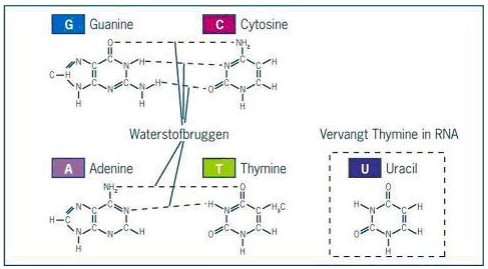
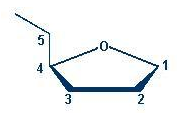
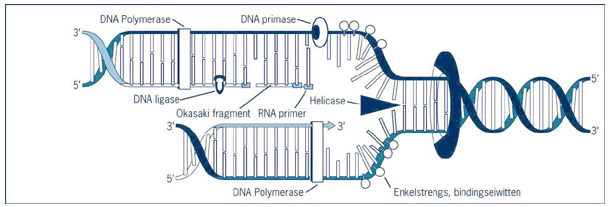
 Lees het volgende artikel:
Lees het volgende artikel:  Maak nu opgave 1 en 2 in je werkdocument. (Het volledige werkdocument vind je hier)
Maak nu opgave 1 en 2 in je werkdocument. (Het volledige werkdocument vind je hier)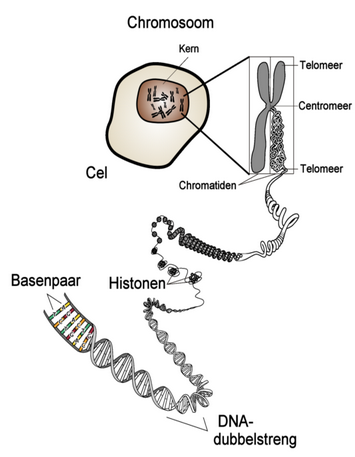


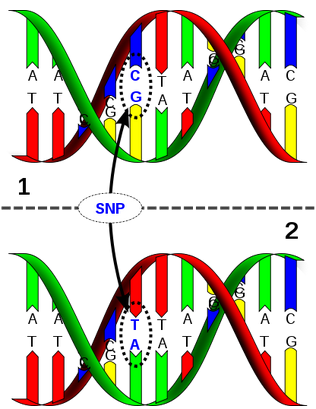
 Thalassemie
Thalassemie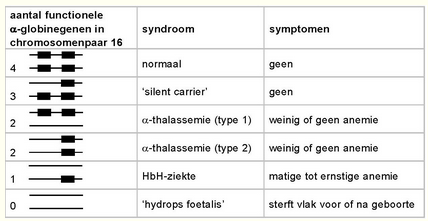
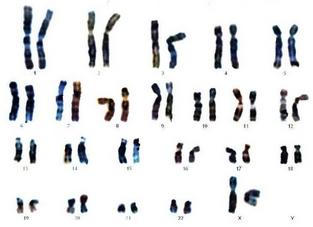






















{kind=link}
Het arrangement E-klas Bioinformatica is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 08-05-2015 09:39:57
- Licentie
-



Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding-GelijkDelen 3.0 Nederland licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding en publicatie onder dezelfde licentie vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding-GelijkDelen 3.0 Nederland licentie.
Dit materiaal is achtereenvolgens ontwikkeld en getest in een SURF-project (2008-2011: e-klassen als voertuig voor aansluiting VO-HO) en een IIO-project (2011-2015: e-klassen&PAL-student). In het SURF project zijn in samenwerking met vakdocenten van VO-scholen, universiteiten en hogescholen e-modules ontwikkeld voor Informatica, Wiskunde D en NLT. In het IIO-project (Innovatie Impuls Onderwijs) zijn in zo’n samenwerking modules ontwikkeld voor de vakken Biologie, Natuurkunde en Scheikunde (bovenbouw havo/vwo). Meer dan 40 scholen waren bij deze ontwikkeling betrokken.
Organisatie en begeleiding van uitvoering en ontwikkeling is gecoördineerd vanuit Bètapartners/Its Academy, een samenwerkingsverband tussen scholen en vervolgopleidingen. Zie ook www.itsacademy.nl
De auteurs hebben bij de ontwikkeling van de module gebruik gemaakt van materiaal van derden en daarvoor toestemming verkregen. Bij het achterhalen en voldoen van de rechten op teksten, illustraties, en andere gegevens is de grootst mogelijke zorgvuldigheid betracht. Mochten er desondanks personen of instanties zijn die rechten menen te kunnen doen gelden op tekstgedeeltes, illustraties, enz. van een module, dan worden zij verzocht zich in verbinding te stellen met de programmamanager van de Its Academy (zie website).
Gebruiksvoorwaarden: creative commons cc-by sa 3.0
Handleidingen, toetsen en achtergrondmateriaal zijn voor docenten verkrijgbaar via de bètasteunpunten. http://www.itsacademy.nl/contact/
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
- (NLT, VWO 5-6) Je gaat met deze module zelf aan de slag als bioinformaticus. Je gebruikt een aantal van de tools die een bioinformaticus tot zijn beschikking heeft en je komt meer te weten over actueel onderzoek op het gebied van bioinformatica. Je onderzoekt de oorzaak van een erfelijke ziekte, schrijft een artikel over forensisch onderzoek en lost een moord op.
- Leerniveau
- VWO 6; VWO 5;
- Leerinhoud en doelen
- Natuur, leven en technologie; Wisselwerking tussen natuurwetenschap en technologie;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 40 uur 0 minuten
- Trefwoorden
- e-klassen rearrangeerbaar
Bronnen
| Bron | Type |
|---|---|
|
https://maken.wikiwijs.nl/userfiles/1bea7671b3218dd53faf0da77e8a0461.swf https://maken.wikiwijs.nl/userfiles/1bea7671b3218dd53faf0da77e8a0461.swf |
Video |
|
https://maken.wikiwijs.nl/userfiles/765253f8f17d1fa15e1d0eb4ea18f0d9.swf https://maken.wikiwijs.nl/userfiles/765253f8f17d1fa15e1d0eb4ea18f0d9.swf |
Video |
Gebruikte Wikiwijs Arrangementen
, Bètapartners. (2013).
0 Start Bioinformatica
, Bètapartners. (2013).
1 Inleiding Bioinformatica
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 1 - DNA
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 2 - mRNA
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 3 - Begrip en inzicht
https://maken.wikiwijs.nl/51424/Bio_Informatica___3___Begrip_en_inzicht
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 4 - Eiwit
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 5 - Begrippenkennis 1
https://maken.wikiwijs.nl/51446/Bio_Informatica___5___Begrippenkennis_1
Eklassen, Toetsmateriaal. (z.d.).
Bio Informatica - 6 - Begrippenkennis 2
https://maken.wikiwijs.nl/51447/Bio_Informatica___6___Begrippenkennis_2