


 Bekijk het filmpje.
Bekijk het filmpje.
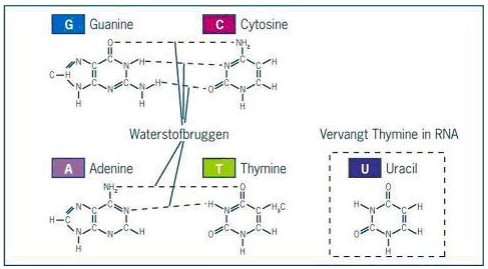
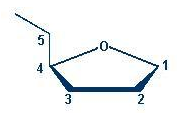
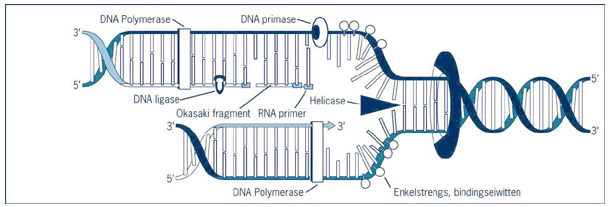
 Lees het volgende artikel:
Lees het volgende artikel:  Maak nu opgave 1 en 2 in je werkdocument. (Het volledige werkdocument vind je hier)
Maak nu opgave 1 en 2 in je werkdocument. (Het volledige werkdocument vind je hier)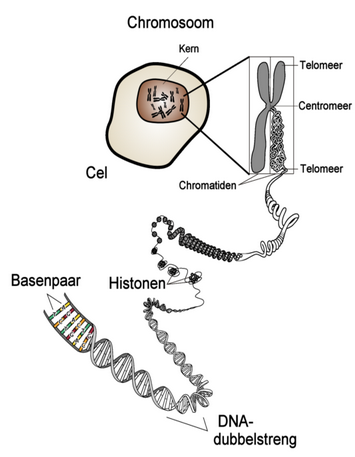


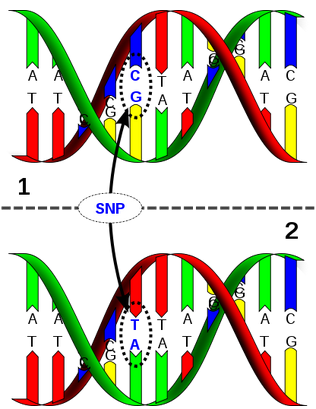
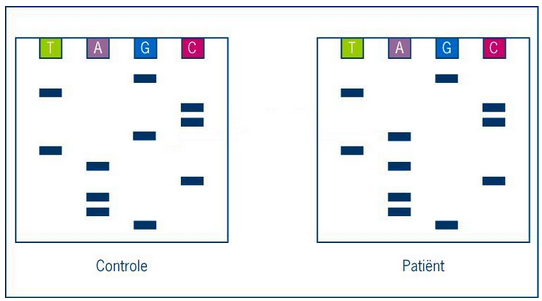
 Thalassemie
Thalassemie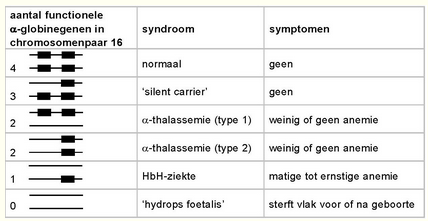





















{kind=link}
Het arrangement Bioinformatica is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 31-12-2014 11:45:22
- Licentie
-



Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding-GelijkDelen 3.0 Nederland licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding en publicatie onder dezelfde licentie vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding-GelijkDelen 3.0 Nederland licentie.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
- test omzetten eklassen naar Wikiwijs Maken
- Leerniveau
- VWO 6; VWO 5;
- Leerinhoud en doelen
- Natuur, leven en technologie;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 40 uur 0 minuten
- Trefwoorden
- e-klassen rearrangeerbaar
Bronnen
| Bron | Type |
|---|---|
|
https://maken.wikiwijs.nl/userfiles/1bea7671b3218dd53faf0da77e8a0461.swf https://maken.wikiwijs.nl/userfiles/1bea7671b3218dd53faf0da77e8a0461.swf |
Video |
|
https://maken.wikiwijs.nl/userfiles/765253f8f17d1fa15e1d0eb4ea18f0d9.swf https://maken.wikiwijs.nl/userfiles/765253f8f17d1fa15e1d0eb4ea18f0d9.swf |
Video |
Gebruikte Wikiwijs Arrangementen
, Bètapartners. (2013).
0 Start Bioinformatica
, Bètapartners. (2013).
1 Inleiding Bioinformatica
, Bètapartners. (z.d.).
Basis e-klassen - verzamel