





Het arrangement Onderzoeksgegevens verwerken is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 12-07-2019 21:18:10
- Licentie
-


Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding 4.0 Internationale licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding 4.0 Internationale licentie.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
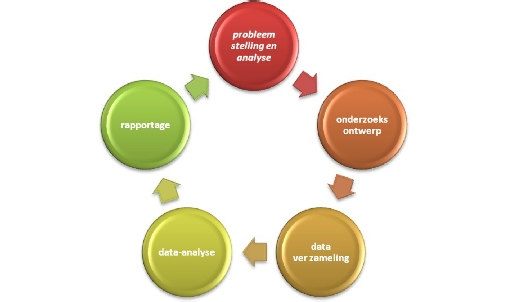
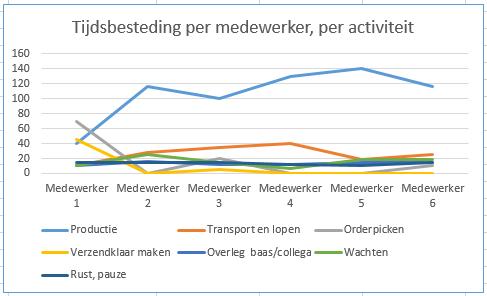
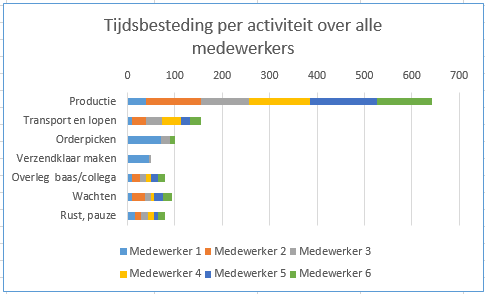
- Bij onderzoek stel je een vraag, en ga je op zoek naar antwoorden. Hiervoor verzamel je gegevens. Dat doe je zowel bij kwalitatief als kwantitatief onderzoek. Uit de verzamelde gegevens ga je conclusies destilleren, en die ga je formuleren als antwoord op je onderzoeksvragen. Hier gaan we vooral in op hoe je de verzamelde gegevens kunt analysen en vertalen naar conclusies. Dit is een HBO-ICT bouwsteen voor Onderzoek in Onderwijs.
- Leerniveau
- HBO - Bachelor;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 2 uur 0 minuten
- Trefwoorden
- bouwsteen, gegevens analyseren, gegevens verzamelen, hbo ict oio, kwantitatieve data, lab, onderzoek, onderzoek doen, onderzoeksgegevens analyseren, technieken voor kwantitatief onderzoek
Bronnen
| Bron | Type |
|---|---|
|
06 - Kwaliteit methoden https://www.youtube.com/watch?v=tMHsjyeEJEg&t=0s&index=7&list=PLqBRJRr0exQc9sI23QrqnSRZd3zDcP9nO |
Video |
|
Onderzoek door Unicef https://youtu.be/HFGVJJMDo4I |
Video |