

 geeft aan wanneer je een opdracht moet maken.
geeft aan wanneer je een opdracht moet maken. Maak nu opdracht 1-1.
Maak nu opdracht 1-1. Maak nu opdracht 1-2.
Maak nu opdracht 1-2.

 Iets anders dan spam zijn scams (scam = oplichting). Scams zijn misleidende e-mails die bedoeld zijn om je in een of ander snood plannetje te lokken. Mensen proberen bijvoorbeeld door je te vertellen dat ze iets gratis aan te bieden hebben jouw adresgegevens afhandig te maken. Sommige scams zijn heel eenvoudig te herkennen, maar andere scams zijn dat niet. Het komt voor dat de scammers met geavanceerde computerprogramma's automatisch afleiden hoe je heet, wat voor dingen je leuk vindt, en wie je kent, bijvoorbeeld van je Hyves pagina. Die informatie gebruiken ze dan om een zo authentiek mogelijk mailtje te sturen. Dan kan het dus zijn dat het lijkt dat een van je vrienden je schrijft dat hij geld van je wil lenen, terwijl het eigenlijk heel iemand anders is.
Iets anders dan spam zijn scams (scam = oplichting). Scams zijn misleidende e-mails die bedoeld zijn om je in een of ander snood plannetje te lokken. Mensen proberen bijvoorbeeld door je te vertellen dat ze iets gratis aan te bieden hebben jouw adresgegevens afhandig te maken. Sommige scams zijn heel eenvoudig te herkennen, maar andere scams zijn dat niet. Het komt voor dat de scammers met geavanceerde computerprogramma's automatisch afleiden hoe je heet, wat voor dingen je leuk vindt, en wie je kent, bijvoorbeeld van je Hyves pagina. Die informatie gebruiken ze dan om een zo authentiek mogelijk mailtje te sturen. Dan kan het dus zijn dat het lijkt dat een van je vrienden je schrijft dat hij geld van je wil lenen, terwijl het eigenlijk heel iemand anders is. Maak nu opdracht 2-1 en 2-2.
Maak nu opdracht 2-1 en 2-2.
 Maak opdrachten 3-1 en 3-2.
Maak opdrachten 3-1 en 3-2. Maak opdracht 3-3.
Maak opdracht 3-3. Maak opdracht 3-4.
Maak opdracht 3-4.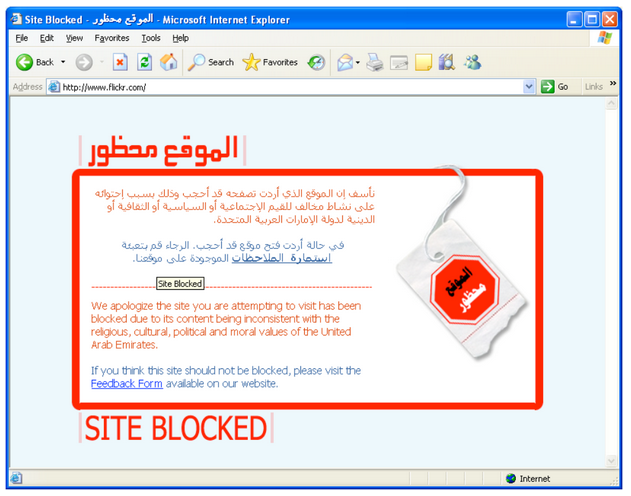
 Maak opdracht 3-5.
Maak opdracht 3-5.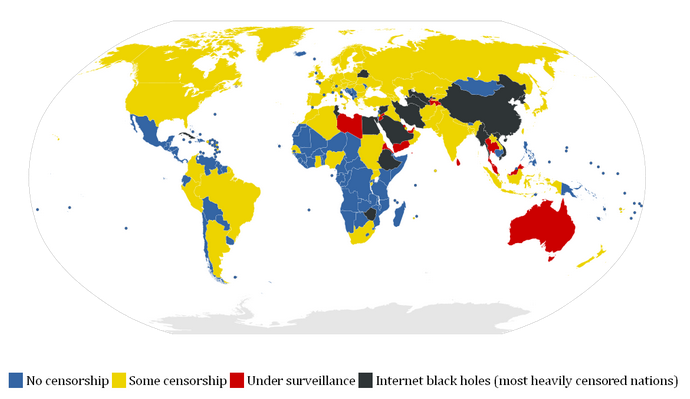
 Maak opdracht 3-6.
Maak opdracht 3-6.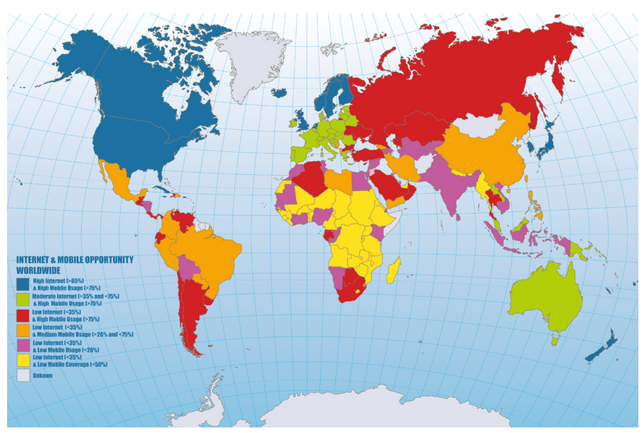
 Maak opdracht 3-7.
Maak opdracht 3-7. Maak opdracht 3-8.
Maak opdracht 3-8. Maak opdracht 3-9.
Maak opdracht 3-9.

 Een bijzondere vorm van een algemene zoekmachine is de metazoekmachine. Hiermee kun je in verschillende zoekmachines tegelijkertijd zoeken. Het resultaat wordt als een lijst gepresenteerd aan de gebruiker. Voorbeelden van metazoekmachines zijn
Een bijzondere vorm van een algemene zoekmachine is de metazoekmachine. Hiermee kun je in verschillende zoekmachines tegelijkertijd zoeken. Het resultaat wordt als een lijst gepresenteerd aan de gebruiker. Voorbeelden van metazoekmachines zijn  Een andere vorm van een specifiek zoeksysteem laat je zoeken binnen een bepaalde website. Het verschil met zoeksystemen als Google Scholar en jaap.nl is dat deze zoekmachines zoeken in een statische hoeveelheid gegevens. Voorbeelden daarvan zijn te vinden op bijvoorbeeld telefoongids.nl of ikea.nl. De laatste website biedt als extraatje een zogeheten avatar ('Anna') aan wie je vragen kan stellen. Bij de meeste zoekmachines kun je zoeken op een trefwoord en krijg je pagina's terug die die zoekterm bevatten. Zoeken met een avatar werkt anders. Stel dat je intypt dat je honger hebt, dan zal de avatar je een antwoord geven dat te maken heeft met het restaurant. Vertel je de avatar dat je dorst hebt, dan vertelt ze dat ze je geen suggestie kan doen. Dat komt omdat van tevoren is bedacht welke woorden in de consumentenvragen moeten matchen met welke producten en diensten. In dit geval is 'honger' wel gelinkt aan restaurant, maar 'dorst' niet.
Een andere vorm van een specifiek zoeksysteem laat je zoeken binnen een bepaalde website. Het verschil met zoeksystemen als Google Scholar en jaap.nl is dat deze zoekmachines zoeken in een statische hoeveelheid gegevens. Voorbeelden daarvan zijn te vinden op bijvoorbeeld telefoongids.nl of ikea.nl. De laatste website biedt als extraatje een zogeheten avatar ('Anna') aan wie je vragen kan stellen. Bij de meeste zoekmachines kun je zoeken op een trefwoord en krijg je pagina's terug die die zoekterm bevatten. Zoeken met een avatar werkt anders. Stel dat je intypt dat je honger hebt, dan zal de avatar je een antwoord geven dat te maken heeft met het restaurant. Vertel je de avatar dat je dorst hebt, dan vertelt ze dat ze je geen suggestie kan doen. Dat komt omdat van tevoren is bedacht welke woorden in de consumentenvragen moeten matchen met welke producten en diensten. In dit geval is 'honger' wel gelinkt aan restaurant, maar 'dorst' niet. Maak opdracht 4-1 en 4-2 en bekijk ook 4-3 (extra stof).
Maak opdracht 4-1 en 4-2 en bekijk ook 4-3 (extra stof).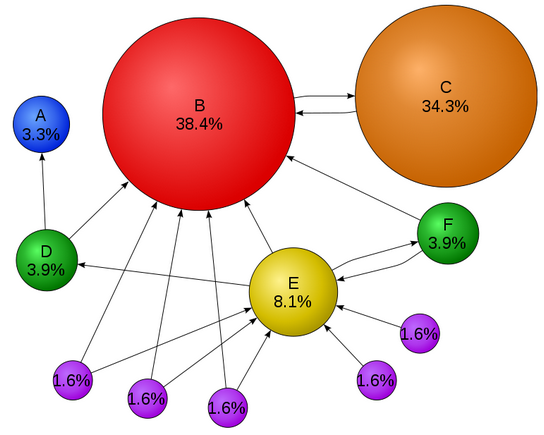
 Lees eerst opdracht 4-4 door, bekijk de documentaire "Google: achter het scherm" van VPRO's Tegenlicht (50 minuten!) en maak dan opdracht 4-4.
Lees eerst opdracht 4-4 door, bekijk de documentaire "Google: achter het scherm" van VPRO's Tegenlicht (50 minuten!) en maak dan opdracht 4-4. Maak opdracht 4-5.
Maak opdracht 4-5. Maak opdracht 4-6.
Maak opdracht 4-6.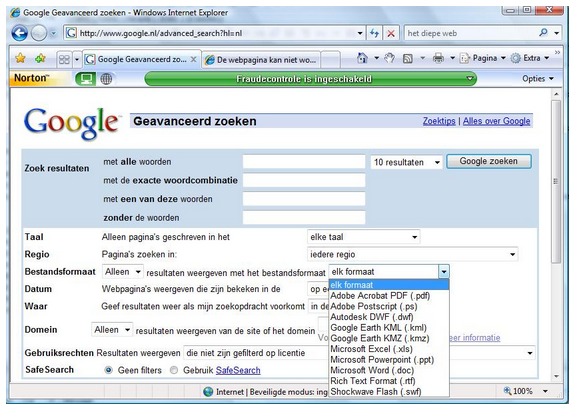
 Maak opdracht 4-7.
Maak opdracht 4-7.
 Maak opdracht 5-1.
Maak opdracht 5-1. Maak opdracht 5-2.
Maak opdracht 5-2.
 Maak opdracht 5-3.
Maak opdracht 5-3.
 Maak opdracht 5-4.
Maak opdracht 5-4.
 Maak opdracht 6-1.
Maak opdracht 6-1.
 Maak opdracht 6-2.
Maak opdracht 6-2. Zoals je misschien al vermoedt na opdracht 6-2b gedaan te hebben, komt de data van DBpedia direct van Wikipedia. Een groot deel van de data op DBpedia komt uit de
Zoals je misschien al vermoedt na opdracht 6-2b gedaan te hebben, komt de data van DBpedia direct van Wikipedia. Een groot deel van de data op DBpedia komt uit de  Dat Semantic Web het probleem van ambiguïteit oplost is een big deal! Als je een website wil hebben die antwoord kan geven op vragen, dan is het belangrijk om de vraag te begrijpen. Dus als je de vraag intypt "hoe snel is die kever?", dan wil je net als bij de Jaguar onderscheid kunnen maken tussen de auto en het dier.
Dat Semantic Web het probleem van ambiguïteit oplost is een big deal! Als je een website wil hebben die antwoord kan geven op vragen, dan is het belangrijk om de vraag te begrijpen. Dus als je de vraag intypt "hoe snel is die kever?", dan wil je net als bij de Jaguar onderscheid kunnen maken tussen de auto en het dier. Maak opdracht 6-3.
Maak opdracht 6-3.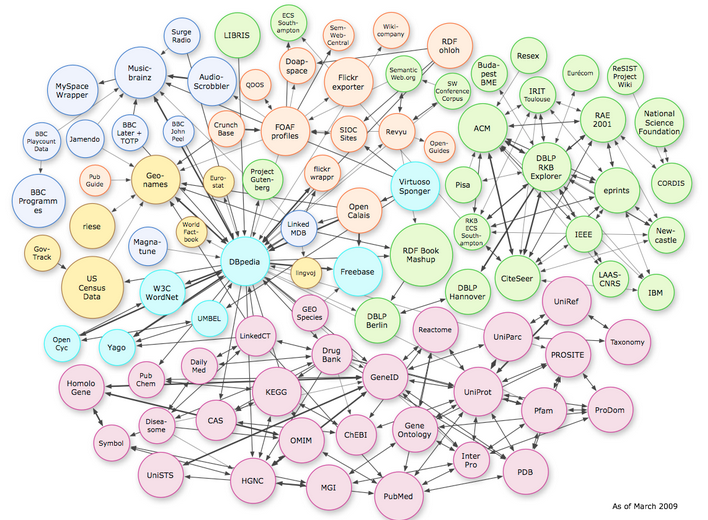
 Maak opdracht 6-4.
Maak opdracht 6-4.Het arrangement Hoe sociaal is internet? is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 15-08-2013 15:56:14
- Licentie
-



Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding-GelijkDelen 3.0 Nederland licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding en publicatie onder dezelfde licentie vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding-GelijkDelen 3.0 Nederland licentie.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
- test omzetten eklassen naar Wikiwijs Maken
- Leerniveau
- VWO 6; HAVO 5; VWO 5;
- Leerinhoud en doelen
- Informatica;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 40 uur 0 minuten
- Trefwoorden
- e-klassen rearrangeerbaar
Bronnen
| Bron | Type |
|---|---|
|
http://www.youtube.com/watch?v=9hIQjrMHTv4 https://youtu.be/9hIQjrMHTv4 |
Video |
|
http://www.youtube.com/watch?v=anwy2MPT5RE https://youtu.be/anwy2MPT5RE |
Video |
|
http://www.youtube.com/watch?v=HPPj6viIBmU https://youtu.be/HPPj6viIBmU |
Video |
|
http://www.youtube.com/watch?v=7dWUrmQrCSE https://youtu.be/7dWUrmQrCSE |
Video |
|
http://www.youtube.com/watch?v=zRwPSFpLX8I https://youtu.be/zRwPSFpLX8I |
Video |
|
https://maken.wikiwijs.nl/userfiles/8f4d7fc990e4b640d36dc6b6fab19b0a.swf https://maken.wikiwijs.nl/userfiles/8f4d7fc990e4b640d36dc6b6fab19b0a.swf |
Video |
|
http://dotsub.com/media/f779c51c-8732-4df8-9836-b5b2df3a4fe4/embed/dut http://dotsub.com/media/f779c51c-8732-4df8-9836-b5b2df3a4fe4/embed/dut |
Video |
Gebruikte Wikiwijs Arrangementen
, Bètapartners. (2013).
1. Introductie internet
, Bètapartners. (2013).
3. Sociale aspecten internet
https://maken.wikiwijs.nl/45921/3__Sociale_aspecten_internet
, Bètapartners. (z.d.).
Basis e-klassen - verzamel