








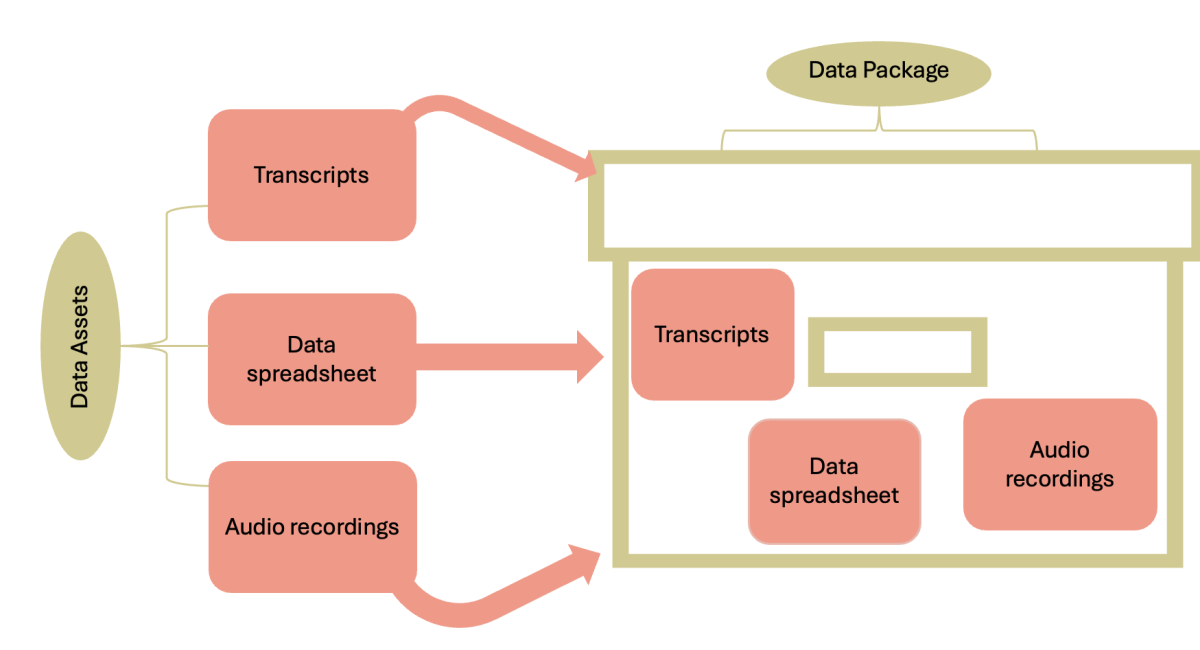
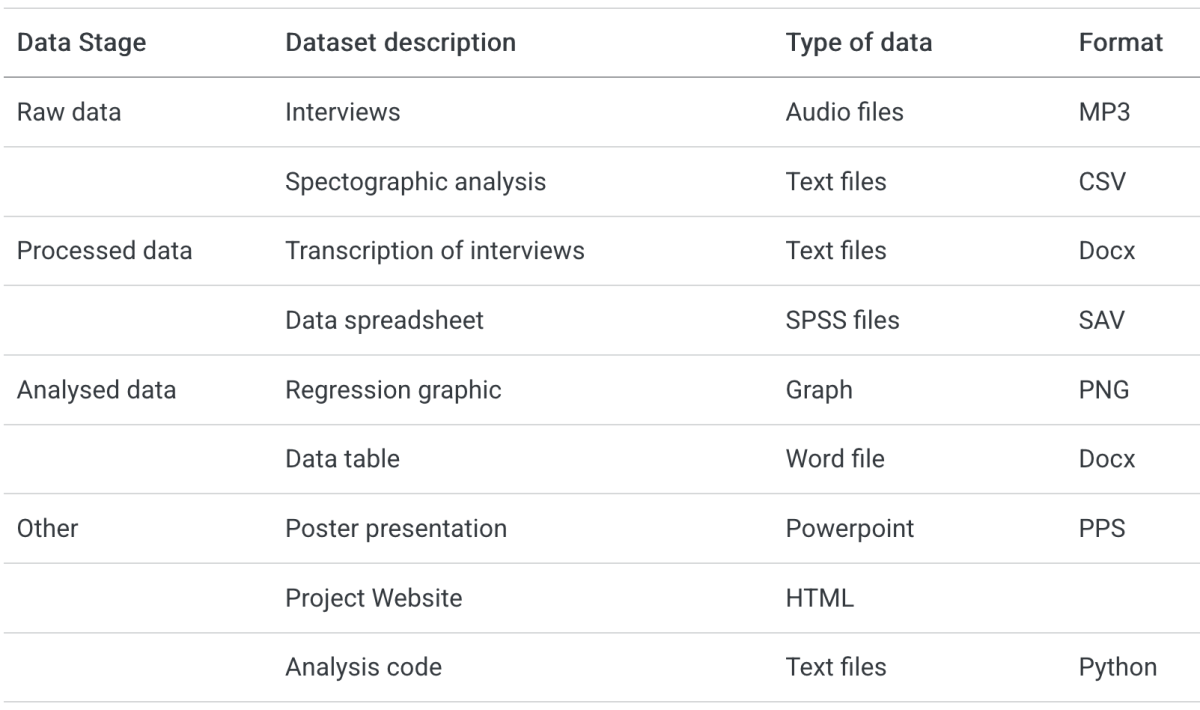
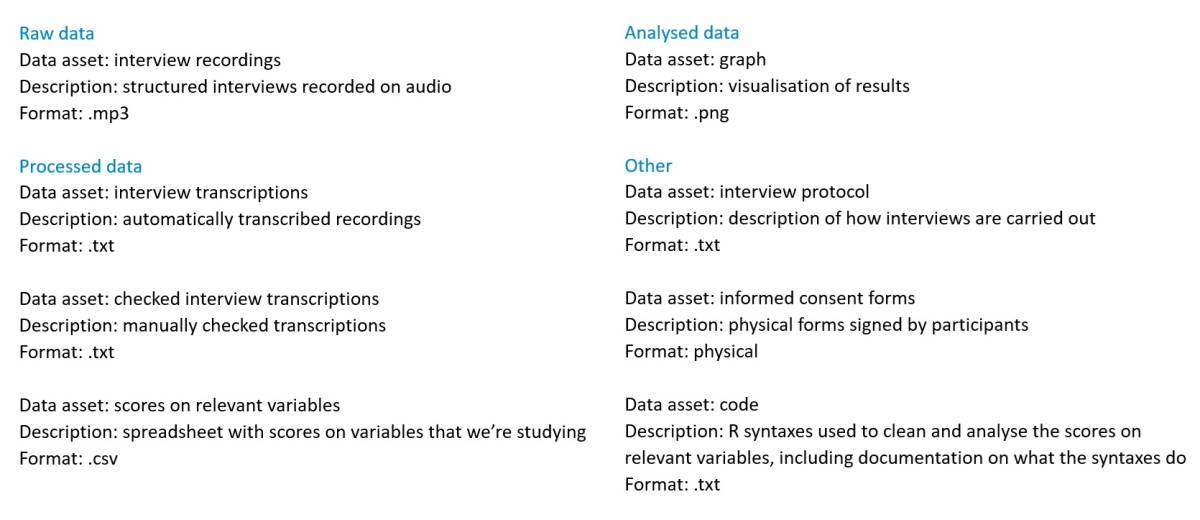




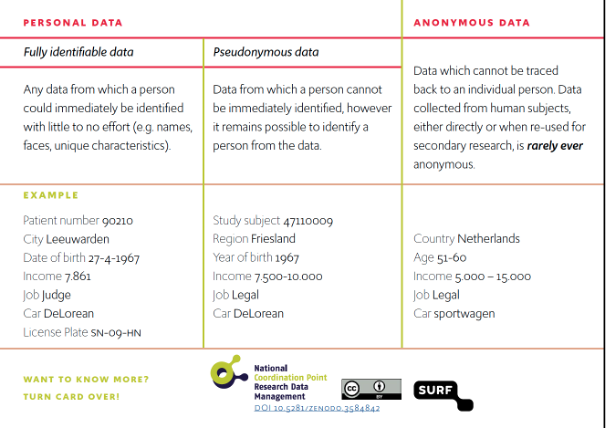






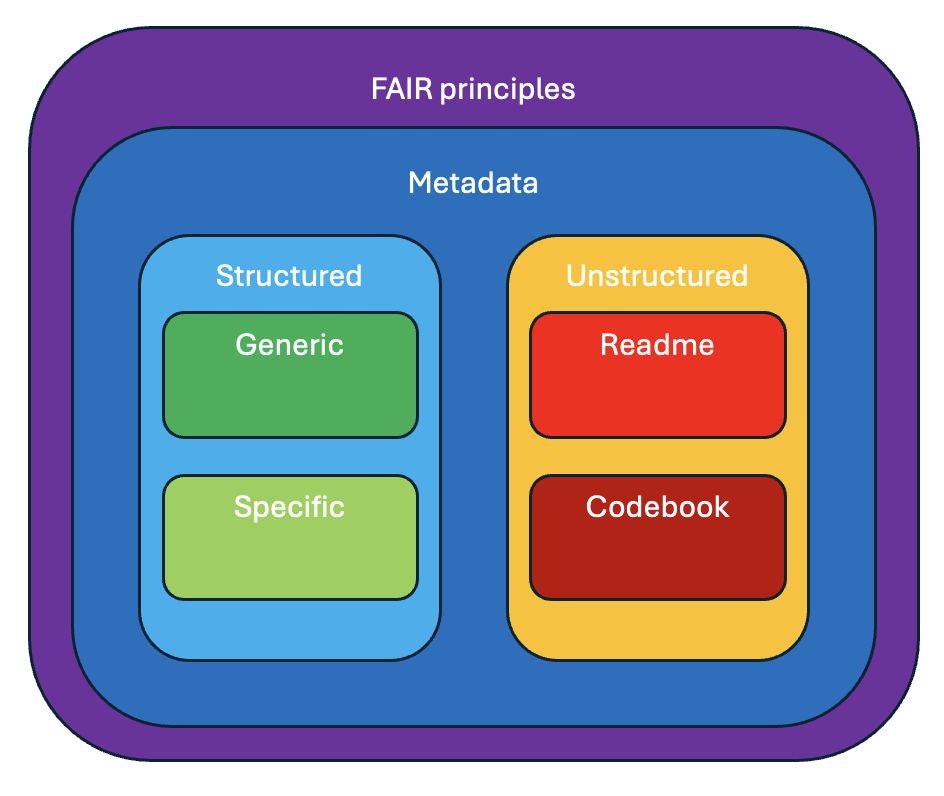
The arrangement Introduction to Research Data Management is made with Wikiwijs of Kennisnet. Wikiwijs is an educational platform where you can find, create and share learning materials.
- Author
- Last modified
- 13-08-2025 12:11:04
- License
-


This learning material is published under the Creative Commons Attribution 4.0 International license. This means that, as long as you give attribution, you are free to:
- Share - copy and redistribute the material in any medium or format
- Adapt - remix, transform, and build upon the material
- for any purpose, including commercial purposes.
More information about the CC Naamsvermelding 4.0 Internationale licentie.
Additional information about this learning material
The following additional information is available about this learning material:
- Description
- Introduction to Research Data Management Audience: Students Level: introduction
- Education level
- WO - Bachelor; WO - Master;
- Learning content and objectives
- Documentaire informatievoorziening;
- End user
- leerling/student
- Difficulty
- gemiddeld
- Learning time
- 3 hour 0 minutes
Sources
| Source | Type |
|---|---|
|
Introduction to Research Data Management https://youtu.be/JovDUak1kuA |
Video |
|
RDM basics https://youtu.be/Ed6GCFrOh3M |
Video |
|
The data package https://youtu.be/fsrsQ71quCk |
Video |
|
Personal data https://youtu.be/xPdfjfSmeQs |
Video |
|
Working with personal data https://youtu.be/Vs8YWHlGCJk |
Video |
|
Data storage https://youtu.be/8C1NWk27wY8 |
Video |
|
Documentation and Metadata https://youtu.be/xEkUQLr2ow8 |
Video |
|
Archiving your data https://youtu.be/0fpJBI3rFLI |
Video |
|
Closing Summary https://youtu.be/gEpTTVOMV_M |
Video |
Used Wikiwijs arrangements
onbekend. (z.d.).
Introduction to Research Data Management - kopie 1
https://maken.wikiwijs.nl/217443/Introduction_to_Research_Data_Management___kopie_1