






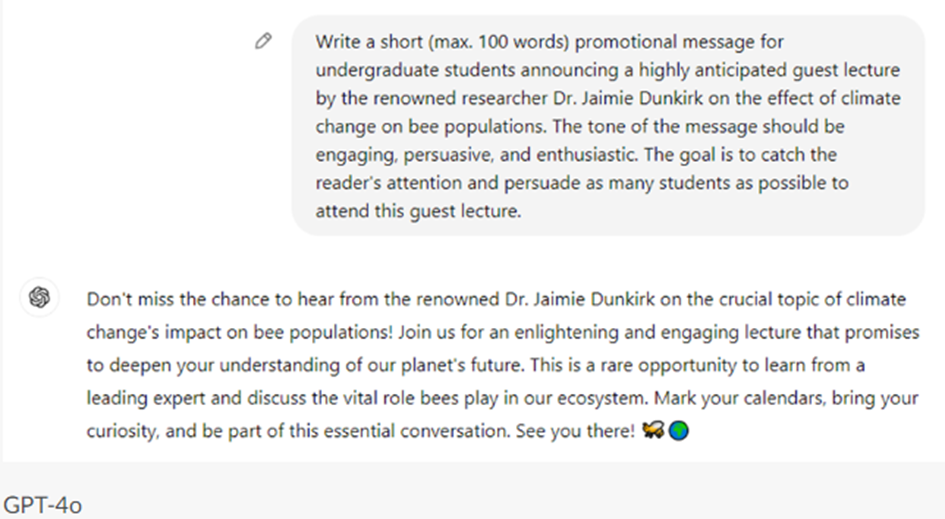
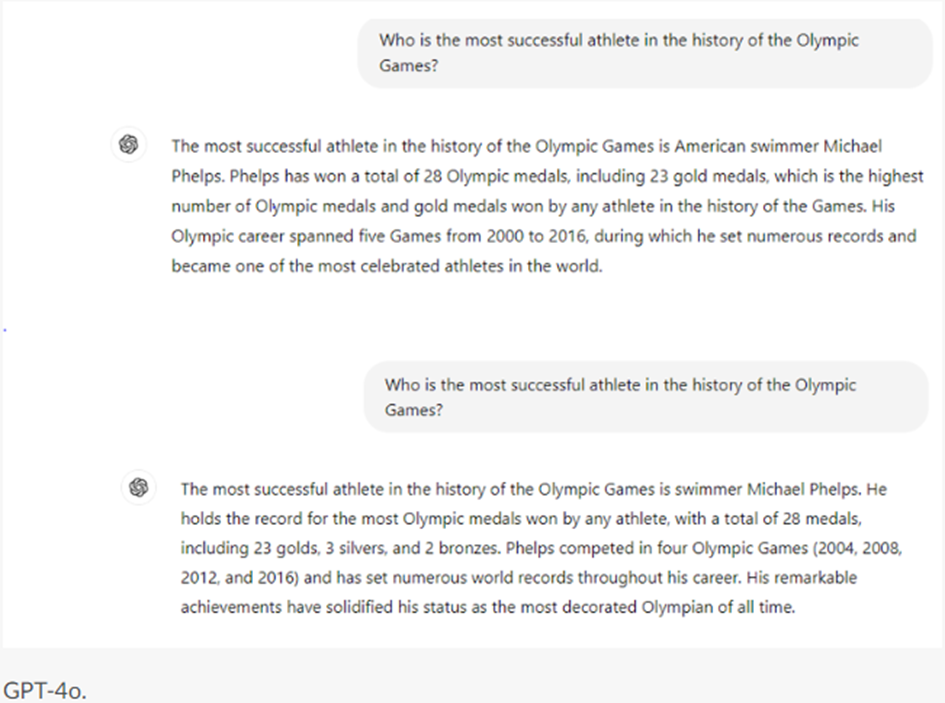



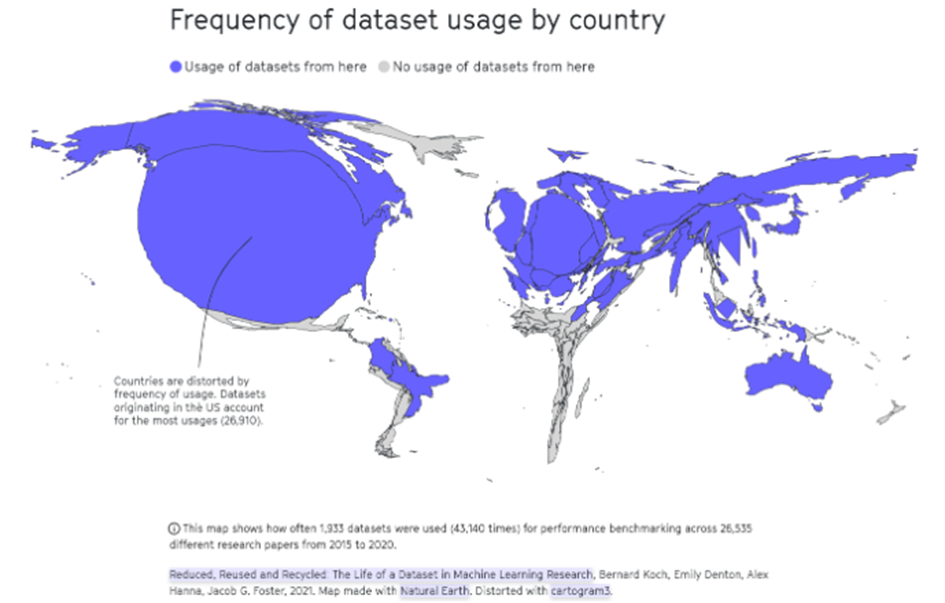





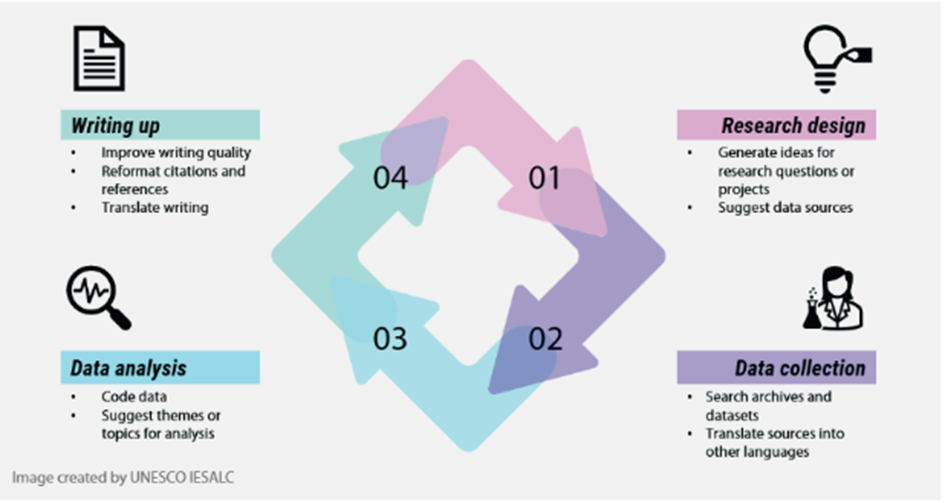
The arrangement Critical AI Literacy is made with Wikiwijs of Kennisnet. Wikiwijs is an educational platform where you can find, create and share learning materials.
- Author
- Last modified
- 08-05-2025 10:05:48
- License
-


This learning material is published under the Creative Commons Attribution 4.0 International license. This means that, as long as you give attribution, you are free to:
- Share - copy and redistribute the material in any medium or format
- Adapt - remix, transform, and build upon the material
- for any purpose, including commercial purposes.
More information about the CC Naamsvermelding 4.0 Internationale licentie.
Additional information about this learning material
The following additional information is available about this learning material:
- Description
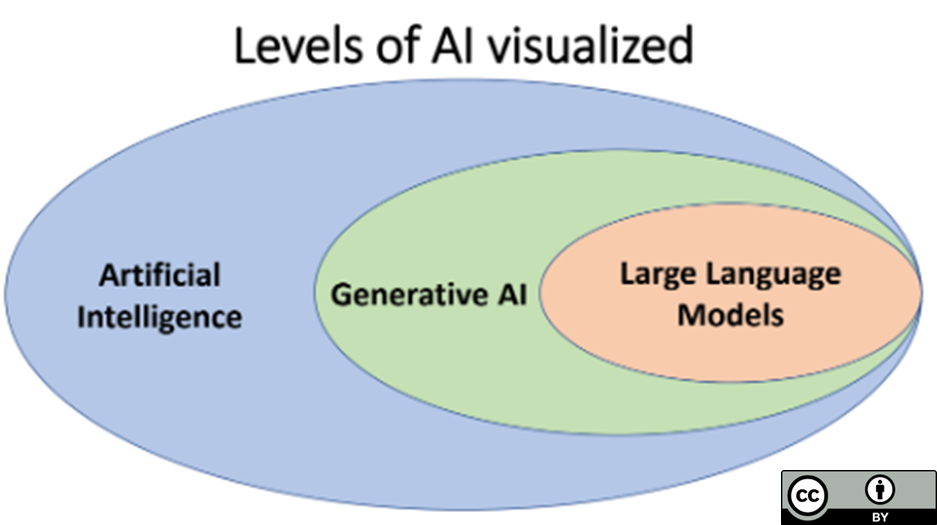
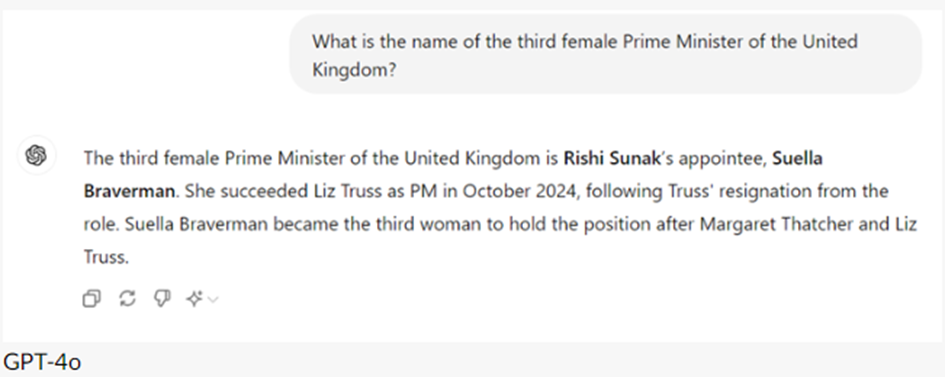
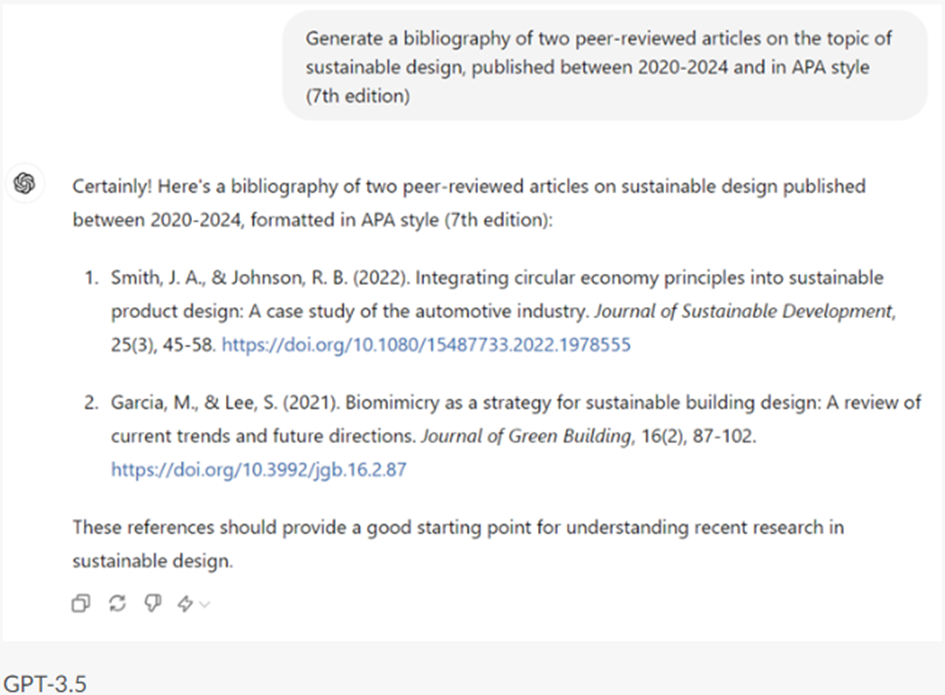
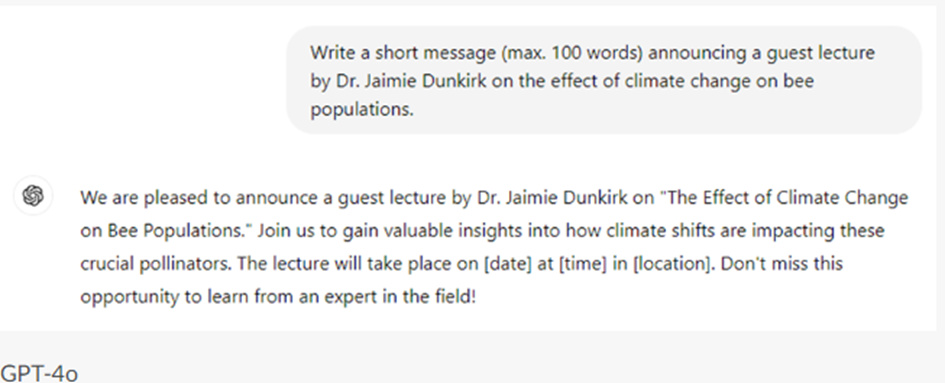
- Dit is een Wikiwijs versie van de Critical AI Literacy module van de Rijksuniversiteit Groningen, oorspronkelijk beschikbaar gemaakt op de Brightspace omgeving van RUG. De module behandelt de definitie, werking, tekortkomingen en kansen, en ethische implicaties van (tekstuele) Generatieve AI modellen. Aan de hand van mix van videos, afbeeldingen, en tekst leert de leerling in ongevaar twee uur of de basis van tekstuele Generatieve AI modellen. Deze training is bedoeld om een basiskennis over Generatieve AI aan te brengen, zodat potentiele gebruikers geinformeerd de keuze kunnen of ze wel of niet een AI tool willen gebruiken. De module benoemt een aantal basisregels en -tips over het goed omgaan met AI tools, maar is niet gericht op het optimaal of meest efficient omgaan met deze tools. De module is oorspronkelijk gemaakt door Lilian Tabois, Martijn Blikmans-Middel, Alicia Streppel, Rob Nijenkamp en Yvonne de Jong. Deze Wikiwijs versie is gemaakt door Martijn Blikmans-Middel
- Education level
- WO - Bachelor; WO - Master;
- Learning content and objectives
- Informatica;
- End user
- leerling/student
- Difficulty
- gemiddeld
- Learning time
- 2 hour 0 minutes
- Keywords
- ai, ai literacy, basic skills, critical literacy, digitial literacy, implications, limitations, technology, use cases, working