Introduction
This course provides an introduction to Research Data Management and guides you in creating your own Data Management Plan (DMP). Throughout the modules, you will explore key processes and best practices in Research Data Management, with a strong focus on applying them to your own project. By the end of the course, you will be equipped to develop a comprehensive data management plan. Additionally, recommendations on appropriate tools and best practices will be provided throughout the course.
Keep an eye out for these boxes, they might have some useful tips and tricks.
Before you start, it is recommended to read over this list of definitions related to data management, these terms will be used throughout the course.
Research Data Management at the VU
Navigate through the pages using the arrows.
Structure of the course
The main text will provide all the information you need to put the subject into practice. Each chapter will be explored through a combination of text, videos, and exercises to enhance your understanding.
At the end of each chapter, you will complete two exercises:
- One will be integrated into the webpage.
- The other will require you to write down key information, forming a solid foundation for your RDM & Privacy Framework, which will be fundamental to developing your data management plan.
Exercise Breakdown:
- Project-Focused Exercise – You will reflect on your own project, evaluating how the chapter’s topic applies to your work. Think of this as preparation for your data management plan.
- Quiz or Task – This will test your understanding of the material. If you answer incorrectly, you can retake it until you achieve a perfect score.
The course follows a logical sequence based on the sections of a data management plan. While it is recommended to go through each section in order, you are free to revisit previous sections or jump ahead if you’re eager to explore a particular topic. The key is to ensure you complete all sections and exercises.
Each chapter will have additional resources which can be used to dive deeper into a topic, here you will find further examples and explanations.
Click the arrow to the right to continue to the next page.
DMPonline
DMPonline is an online tool that is used to create, develop, and gain feedback on your data management plan.
Various templates exist in which you can set up your DMP. We strongly recommend that you use the VU template, which is called VU DMP template 2021 (NWO & ZonMw certified) v1.4. Below you’ll find an explanation of how to access this template. If you need to write a DMP for funding agencies NWO, ZonMw or ERC, you can use the VU template as well.
VU template
You can find the VU DMP template in DMPonline. It includes concise guidance on how to complete your DMP.
You can select the VU template by taking the following steps (see also the picture below).
- On your dashboard, click on
Create plan. - Enter the title of your research project (you don’t have to select the check box for mock testing).
- Select
Vrije Universiteit Amsterdamas your primary research organisation. - For the question on primary funding organisation, select the check box on the right, saying that no funder is associated with your plan.
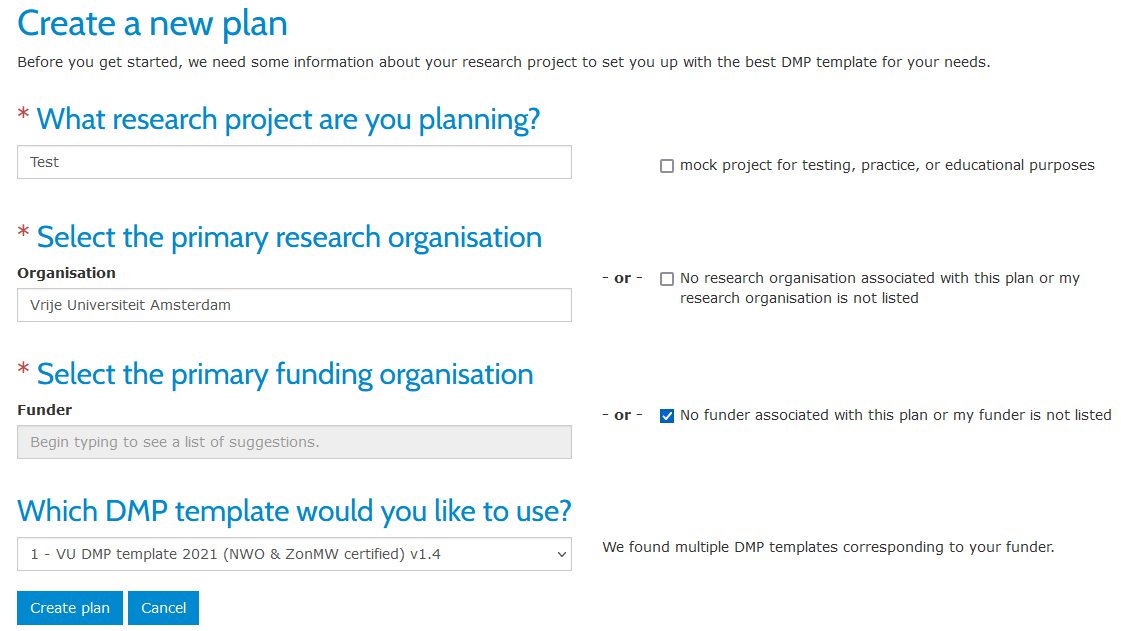
If you’re aiming to write a full DMP based on VU Amsterdam DMP template, please make sure you don’t select the GDPR registration form.

Research Data Management Basics
Effective research data management is essential for ensuring the quality, integrity, and success of your project. Every decision you make regarding your data; from collection to dissemination can have a significant impact on your research outcomes. By understanding the key stages of the research process and planning your activities accordingly, you can identify potential challenges early, implement necessary safeguards, and maintain a structured approach to your work.
This chapter explores the Research Lifecycle, a framework that outlines the various stages of research, helping you visualize your project from start to finish. By mapping out your tasks within this lifecycle, you can create a clear timeline, improve efficiency, and anticipate potential roadblocks, ultimately leading to a smoother research experience.

The Research Data lifecycle
How you manage your research data has a direct impact on the overall quality and integrity of your research. To fully understand how certain decisions affect your project, it is important to identify the key stages of research and map out your activities accordingly. By doing so, you can easily recognise potential bottlenecks in the project, implement appropriate safeguards, and take a proactive approach to your project. Of course, there will always be unexpected challenges that arise in a project but with good management and planning, these can have less impact on your progress.
The Research Lifecycle is a commonly used framework that outlines the stages involved in research. It maps research from the point of conceptualization to the final stage of dissemination. The lifecycle is broken down into 6 stages:
- Discover and Initiate
- Plan and Design
- Collect and Store
- Process and Analyse
- Document and Preserve
- Publish and Share
Often tasks will span over multiple stages, but in general we can categorise most tasks into one of the six stages of the research lifecycle. If you can map out the tasks which will take place in your research, it will be easier to create a clear timeline and plan for your overall project.
If you fail to plan, you plan to fail.
Follow the arrow to discover what happens at each stage.
Discover and Initiate
In this initial stage of research, it is common to explore your ideas and look at what data is relevant to your research question. This may include such tasks as evaluating existing datasets, discovering relevant literature and formulating ideas.
If you are reusing a dataset, you should ensure that you are doing so in an ethical and suitable manner. Considerations such as licensing, privacy and suitability of the dataset should be made. Sometimes an agreement may be required to access the dataset, if so, you should contact the data steward of your faculty.
Plan and Design
Before you begin collecting your data, it is important to spend time planning how you will do so. In this phase you will write your research proposal, create your data management plan, develop informed consent and information statements, find out which regulations apply to your research (GDPR, WMO), get in touch with support networks (RDM, privacy, grant advisors) if required, and determine if there are any legal, ethical or financial requirements for your project.

Collect and Store
Now that you are planned and ready to go, it is time to start collecting your data! The tools you use to collect your data will be different depending on your project, for example you may use Qualtrics, an MRI machine or a recording device. Check out this link for more information about the data collection tools available to VU researchers. It is important to be diligent when documenting your data collection process, you should record the steps you have taken to collect the data. This not only ensures the process can be replicated by others but also ensures you can understand your dataset at a later stage.
Where you store your research data will be determined by the project's needs and the sensitivity of the data. Luckily the VU has a storage finder tool which can help you make the right decision. If in doubt, always reach out to a Data Steward at your faculty.
If you are reusing a dataset, you should ensure that you are doing so in an ethical and suitable manner. Considerations such as licensing, privacy and suitability of the dataset should be made. Sometimes an agreement may be required to access the dataset, if so, you should contact the data steward of your faculty.

Process and Analyse
Once you have finished data collection, it is time to answer your research question. You are now ready to process and analyze your data. In this phase, you will clean your data, again the specific tasks this entails will depend on the data you have collected. This may include formatting your data, removing duplicated and ensuring consistency. You may also use other tools such as transcription software, don’t forget to make sure the tools you use are safe and supported by the VU. If you are unsure if a tool is supported by the VU, reach out to the Research Data Support Desk.
Next you will analyze your data to answer your research question. If you are developing code (R, Python, SPSS) to analyze your data, don’t forget to include comments and create a codebook. You may also use other tools such as Atlis.TI.
Again, you should be documenting the steps you take while processing and analysing your data throughout your project. It is also important to consider version control at this point.

Document and Preserve
Now, your project is finished and it's time to move your data from active research storage to the archive. The archive is a long-term storage space which ensures that once the data is submitted it cannot be altered or lost. It is VU policy to archive your data for (at least) 10 years after publication. This is an important stage of research as it ensures integrity and transparency in your research.
A dataset consists of the following documents:
-
Raw or cleaned data (if the cleaned data has been archived, the provenance documentation is also required)
-
Logbook or lab journal (when available, dependent on the discipline)
-
Software (& version) needed to open the files when no preferred formats for the data can be provided

Publish and Share
The research landscape heavily promotes Open Science, and under this umbrella falls Open Data Publishing. Sharing your data with others can help promote collaboration, further scientific research and increase the recognition of your research. Publishing your data in a repository is a great way to share your research and increase your research outputs. However, there are instances where openly publishing all your research data is not possible. It is important to discuss publishing data with a Data Steward if any of the following apply to your research:
-
Personal data (GDPR)
-
Intellectual Property (Commercial collaborators, external collaborators)
-
Government secrets
-
Sensitive topics
Once you have determined what data you can and cannot share publicly. You can now determine which repository you will publish in. You can find out more information on specific repositories here. Each repository will have their own requirements, but it is always required to include the code you used to analyze your data, clear reuse documentation along with a reuse license.

Summary
Organisation and planning is key to a successful research project. Best practices and policies are often in place to ensure data management is considered at all stages of the research lifecycle. However, data management is not just an administrative task, it is key for promoting good scientific practices and for many more reasons.
Good data management helps: increase the integrity of your research, contribute to the impact of your research, improves the quality of your research, supports future reuse of your data and makes your job easier as a researcher!
Task 1:
Think of your own research, can you imagine what tasks you will take on?
- Write down all the different tasks which you anticipate will occur during the entire research project. The more detailed you make this list, the better overview you will have of your project.
- Once you have a complete list created, assign them to the appropriate stages of the lifecycle. If some tasks will take place over multiple stages, you can note them in both sections.
This list can be the starting point for your planning, if you want to go one step further you can place these tasks on a timeline. This will help keep you focused and help you set realistic goals.
Some examples of tasks are: selecting a research topic, choosing a research methodology, thinking about resources
(money, people), discussing ideas with colleagues and/or supervisors, writing down and finalising details of research proposal the project’s research design, preparing and submitting an application for ethics approval, arranging software needed for data analyses, preparing manuscripts for journal publication, writing a data management plan, selecting a data storage location, etc...
(money, people), discussing ideas with colleagues and/or supervisors, writing down and finalising details of research proposal the project’s research design, preparing and submitting an application for ethics approval, arranging software needed for data analyses, preparing manuscripts for journal publication, writing a data management plan, selecting a data storage location, etc...
The VU's data management plan template is modeled from the research lifecycle, so you can use the information gathered throughout the course when designing your own data management plan.
Task 2:
Toets: Research Data Life Cycle Summary
Data package and Data assets
Research data is often visualized as numerical data, however research data is full of variety and can differ immensely. It includes all physical and digital information collected, observed, generated, or created for analysis. Additionally, administrative documents such as key files, informed consent forms, and interview guides are essential components of research data that contribute to the integrity of a project.
Understanding how data is structured within a research project is crucial for effective data management. Each individual piece of data or documentation is known as a Data Asset, which may evolve as the research progresses. These assets collectively form a Data Package, the final compilation of all collected, analyzed, and processed data, along with the necessary contextual information to ensure its future usability.
In this chapter, we will explore the different types of data assets, how they change throughout the research process, and how to effectively organize them. By properly managing your data assets, you can enhance the quality, reproducibility, and long-term impact of your research.
What is a data asset?
When we think of research data we often only consider numerical data, however this does not truly reflect the diversity of research data. Research data includes all information (physical and digital) collected, observed, generated or created for the purpose of analysis, to produce and validate original research results. Administrative documentation such as a key file, informed consent and interview guides should also be recognized as important elements of research data.
The term 'Data Asset' refers to an individual piece of data or documentation within a project. This can be a csv file containing your raw data, the transcripts of an interview, or the results of an EEG scan. These data assets may transform throughout your project, for example, after you have cleaned a data set, you will then have a new data asset. This is considered a new data asset and should be treated as one. As you progress through your project you will create and collect various data assets.
The accumulation of all these data assets creates a 'Data package'. This is the final product of your research data, it should be a collection of the data you collected, analysed and processed, the contextual information that describes the data (metadata), the guidelines and protocols you followed, information on how the data was collected and what is can be used for in the future and any other information which would be relevant to understand, test and reuse your dataset. When it comes to archiving, this will be important.
Think back to task 1 of the previous chapter, can you think of the data assets which will be created during each task?
Throughout the lifetime of a project, many data assets will be collected and created, the organisation of these data assets is the key to good data management. You can categorize your data assets into four groups:
- Raw Data
- Processed Data
- Analysed Data
- Other Data
Raw Data
Firstly, you will have your raw data, this is data which has not been analyzed, cleaned or altered in any way since its creation. This will always be your starting point, even if you are reusing a dataset. The data that you begin with will be considered your raw data. This may include the recordings of interviews, responses to a questionnaire, measurements collected via a device, etc...
If a laboratory extracts the data for you, you can consider the data you receive from the lab your raw data.
Processed Data
Once you have collected the raw data, this will then be used to create your processed data. This is raw data which has been altered in some way. This includes processes such as cleaning the data, pseudonymizing the data and performing statistical analysis. These processes result in a new dataset, one which can then be used to answer your research question.
Analysed Data
Then you have your analyzed data. This category is not that different from processed data and in some cases, there is no difference between the two. In this category you would include data visualization and other files which represent the ‘final’ version of the data.
Other Data
Finally, you have the remainder of your data assets. These fall into the category of Documentation. The documentation you collect throughout your project usually consists of files which add context to your other data assets. You may also include any protocols or guidelines you used. An example of documentation would be Codebooks, ReadMe files, interview guide, metadata files, and the documentation of your processes.
Examples
Below are two examples on how to structure your data assets.
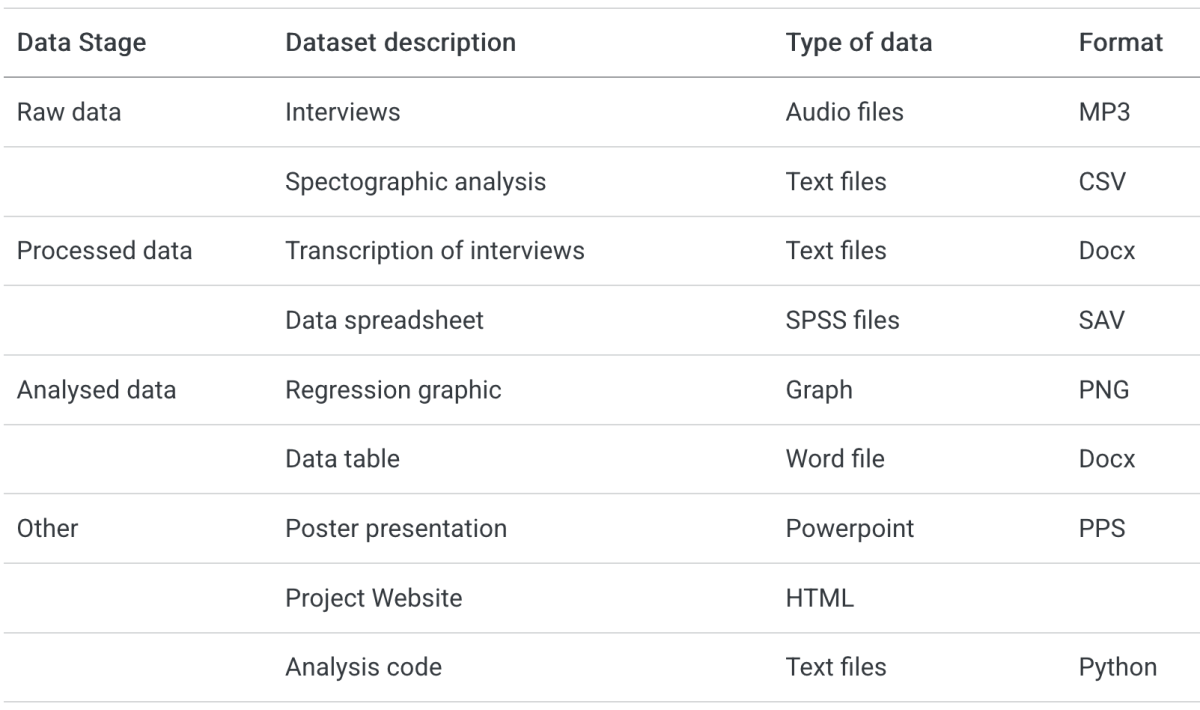
The first example consists of interview data which gets transcribed and analysed by use of a self-written R code.
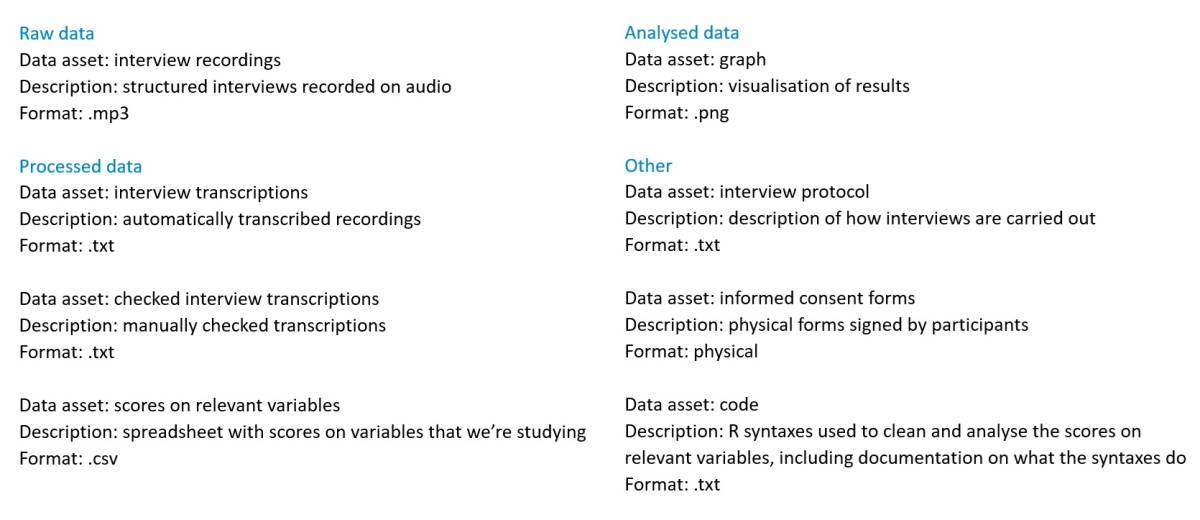
The example below consists of experimental physical data.

Summary
Within a research project, individual pieces of data or documentation are referred to as Data Assets. These assets evolve throughout the research process, such as when raw data is cleaned or transformed into a new version. Properly tracking and managing these assets is essential for maintaining data integrity.
The final collection of all data assets forms the Data Package, which includes:
- Collected, analyzed, and processed data
- Metadata that describes the data
- Research protocols and guidelines
- Information on data collection and potential future use
A well-organized data package is key to effective archiving and future reuse. To streamline data management, data assets can be categorized into four groups: Raw Data, Processed Data, Analyzed Data, and Other Data. Proper organization of these assets ensures clarity, reproducibility, and long-term usability of research data.
Task 1:
Think about the data assets you will collect for your research project.
- List all the data assets you will create and collect for your project, again the more detail the better.
- Categorise them into raw, processed and analysed, think of the data assets which will transform throughout your project and the ones which will remain consistent.
Having a complete list of data assets helps in the later stages of the data management plan and gives you an overview of your data throughout the entire research lifecycle.
Toets: Research Data Assets
Personal Data
In today's research landscape, handling personal data responsibly is a critical aspect for ensuring the integrity of your project and the protection of individuals' rights. Personal data refers to any information that can identify a person, whether directly or indirectly, and includes a wide range of data types such as names, contact details, or even more sensitive information like health records or interview responses.
As you collect and process personal data in your research, it is essential to be aware of the legal frameworks governing its use. One of the most important regulations in this area is the General Data Protection Regulation (GDPR), which sets strict rules on how personal data should be managed, stored, and shared to safeguard privacy.
This chapter will guide you through the key concepts surrounding personal data, its legal protections under GDPR, and how to ensure your research complies with these regulations. You will learn about the rights of individuals, the responsibilities of researchers, and the measures necessary to protect personal data throughout its lifecycle, from collection to storage and eventual disposal. By understanding and applying these principles, you can ensure that your research respects privacy while maintaining high ethical standards.

What is personal data?
‘Personal data’ refers to any information related to an identified or identifiable natural person.
This means personal data is any information on a living person. This information can be objective or subjective. This information can differentiate one individual from another and says something about them.
In general, if you are using data collected/ about people, it is always best to assume it is personal data.
Personal data can be objective or subjective:
Subjective personal data
In this example case, Caspar thinks Lily is sociable and engaging. This data reveals something about both Caspar (his opinion) and Lily (that she is sociable and involved, according to Caspar).
Objective personal data
An example of objective information: Caspar is 1.70 m tall.
Personal data is quiet a general term and describes more data types than what we may initially think, it does not only consist of information which can be linked directly to an individual but also includes information which can be used as a puzzle piece to re-identify someone.
Directly identifiable personal data includes information such as name, address, photographs/video recordings of faces, for which little to no effort and no additional information are required to determine to whom the data belong. These types of data are what we most commonly relate to as personal data. However it is important to be aware that personal data can also be indirectly identifiable.
Indirectly identifiable data require more effort as well as additional information to determine to whom the data belongs to. Indirectly identifiable personal data include genetic information, data that are unique to an individual, datasets with extreme or unusual values (e.g. extreme physical measurements unique to elite athletes, highly unique employment history) or any other characteristics about a person (e.g. ethnicity, gender, occupation and/or education) that when combined into one record, can single out that person as unique in your dataset. Indirectly identifiable data may not immediately identify an individual, but they do provide the potential for identification of that individual
When collecting any data from participants, it is best practice to minimise the amount of personal data collected. You should think critically about why you need to have specific information of your participants and always strive for miminising the personal data you collect.
The General Data Protection Regulation (GDPR/ AVG)

The GDPR outlines an additional category of personal data which requires some additional considerations. This is the special categories of personal data. When working with special categories of personal data there are stricter conditions:
-
Racial or ethnic origin
-
Political opinions
-
Religion or philosophical beliefs
-
Trade union membership
-
Health
-
Including any type of physical measurement, assessment of mental well-being or cognitive function, even in a non-clinical population
-
Sex life or sexual orientation
-
Personal data concerning criminal convictions and personal data concerning unlawful or objectionable conduct for which a ban has been imposed
-
Biometric data (fingerprints, iris-scans)
-
Genetic data
Contact your Privacy Champion if you think this applies to your research.
7 principles of the GDPR
You are not expected to be a privacy expert, instead you should understand why the privacy of your participants is important and requires additional care and considerations when planning your research. Under the GDPR, there are seven key principles for data protection. You should keep these in mind when working with personal data.
Lawfulness, fairness and transparency:
-
Have a valid legal ground for processing personal data.
-
Be clear, honest and open with your participants on how you will process their data.
-
Process data the data in a way which is fair.
Purpose limitation:
- Be clear and specify why the data will be processed from the start of the project.
- Only use the data for this purpose.
- Inform your participants about the purpose of data processing.
Data minimisation:
- Only collect data which is relevant to your research.
- Be critical of why you need someones personal data, if it is not necessary don't collect it.
- Periodically review the personal data you have, and delete what is no longer required.
Accuracy:
- Take reasonable steps to ensure data is accurate and up to date.
- If you discover data is incorrect, take steps to resolve this and document the process.
Storage limitation:
- Be clear and transparent with participants regarding the retention period of their data.
- Do not keep data for longer than necessary.
Integrity and Confidentiality:
- Implement the appropriate measures to ensure the protection of personal data.
- Speak to your supervisor or data steward to ensure these measures are correct.
Accountability:
- Take responsibility for how you handle your data.
- Document clearly how you will handle your data.
- Be aware of the processes for reporting a data breach and follow if necessary.
Summary
Personal data applies to any data which can be used to (re)identify a person. It is important to remember that we live in a world with increasing datafication, meaning more and more personal data is available which can be used to re-identify participants. Protecting personal data means being aware of ways in which identification can be possible, for example:
Someones job title, years of experience and field they work in may not be directly identifiable by themselves. But combined with data available publicly on LinkedIn this information can be used to identify someone and find further information.
If you are unsure whether your data would be considered personal data, reach out to your supervisor or a Data Steward.
Task 1
You will need the list of data assets created in the previous chapter to complete this task.
- Evaluate each data asset and determine whether they contain any personal data.
- Take note of each data asset that contains personal data.
- Take note of each data asset that contains a special category of personal data.
Toets: Is this personal data?
Working with personal data
This chapter will explore essential aspects of working with personal data, including the legal grounds for processing such data. You will learn about the different legal bases for collecting and using personal data, such as consent, public interest, and legitimate interest, and how to determine which one applies to your research.
Additionally, we will dive into the differences between anonymous and pseudonymous data. Understanding these distinctions is key to data protection, as anonymous data cannot be traced back to an individual, while pseudonymous data still allows for potential identification with additional information. You will explore how these types of data impact privacy risks, legal requirements, and the methods for managing data throughout your research project.
By the end of this chapter, you will have a clearer understanding of how to handle personal data ethically and legally, ensuring compliance with data protection laws while protecting the privacy of individuals involved in your research.
Legal ground
You will often hear the term 'processing' when discussing personal data. This is an umbrella term which refers to anything you do to the the data. This can include collecting data, reusing data, cleaning data, (long term) storage, sharing data, and even deleting data.
When processing personal data, we must first have a 'legal ground'. We touched a little on this in the last section, but now we will learn what this means in practice. In research the most common legal ground for processing personal data is 'informed consent'. It is a researchers responsibility to appropriately inform their participants on what will happen to their data, what is will be used for and how they can report issues or concerns relating to data privacy. This is typically done within 2-3 documents:
-
Informed consent:
- This form clearly describes the data you will collect and for what purpose. It should include an outline of what is expected during participation. If you intend to make data available for reuse, this should also be addressed. The language and terminology used in the form should be comprehensible and tailored to the participant considering the target audiences age, capability and language skills. Consent should always be voluntary and participants should always be allowed to cease their participation at any stage of the research.
-
Information letter:
- This letter describes what the data is being collected for and gives additional insight into the research project. This should also be understandable and participants should have time to ask questions and raise any concerns they have. Participants should get a copy of the information letter to keep so they can refer back to at a later stage.
-
Privacy statement (sometimes not required):
- This statement should clearly outline all processing activities that will occur with the data, who can access the data, and inform participants on how to report concerns of data misuse/ data protection.
There are other legal grounds to process personal data within the GDPR. It is required for a member of the VU privacy team to evaluate whether they are suitable. So, do not make this decision for yourself. If you think they may apply to your project, reach out to the faculty Privacy Champion.
Templates are available for all the documents listed above, contact either your supervisor or Data steward to access these.
Anonymous and pseudonymous data
When collecting data from people, it is always best to minimise the amount of personal data you collect from your participants. If possible, you should not collect directly identifiable information unless it is required to answer your research question. This helps protect the privacy of your participants and decreased the likelihood of re-identification.
If personal data must be collected, it should be de-identified as much as possible. Two terms which are used to describe de-identification are anonymous and pseudonymous. They do not mean the same thing.
Anonymisation does not equal pseudonymisation
Anonymous data means a participant can never be re-identified from the data contained in a dataset, even if the data is merged with another dataset. Full anonymity is very difficult and usually not achievable without removing all the 'useful' information that is good for research.
Examples of anonymous data:
- Aggregated data (17% of participants have preference X)
- randomised data, within a group of participants, the data have been randomly swapped so that the participants cannot be traced back to a person (simulation dataset for universities)
Be aware: small sample sizes and unanimous answers can impact the anonymity of a dataset, this should be considered when evaluating whether you can classify your data as truly anonymous.
Pseudonymous data means a participant can still be re-identified from the dataset. However, they cannot be identified without some additional information.
Techniques for pseudonymisation:
- removing directly identifiable information such as name and replacing it with a random key (key file)
- generalisation (categorising variables into groups)
- removing outliers
If you use a key file to store the link between identifiable information and the associated key file, this should be stored in a separate location to the remainder of your research data. This increases the security of your data and reduces the risk of unauthorised re-identification of participants if your research data is compromised.
Below you will find a table which portrays the differences between terms.
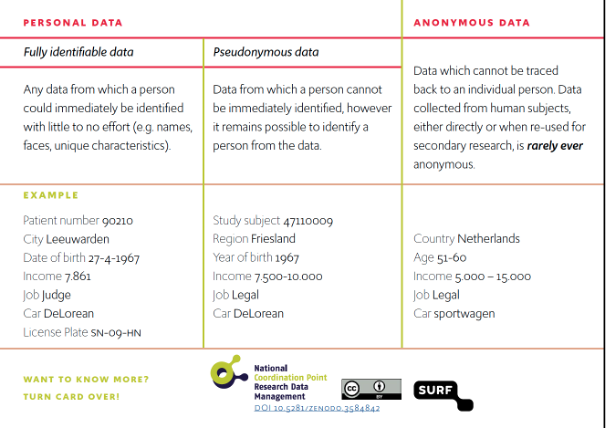
De-identification table
Summary
When working with personal data you must ensure you are complying with regulatory and ethical guidance. This requires you to have a level of awareness regarding your responsibility as a researcher when handling personal data. It is not expected that you will be a privacy expert but you should think critically when collecting personal data and reach out for further support if necessary.
In this chapter we looked at what a legal ground is for processing personal data and the difference between anonymous and pseudonymous data. The following tasks will demonstrate how this knowledge is applicable in the research process.
If you think your legal ground is not informed consent, contact your privacy champion to discuss this further. The decision to use a legal ground outside of informed consent can only be made with insight from a privacy expert.
Task 1:
Thinking of the project you will work on, consider what legal ground will be used when processing personal data. List all the data collected from participants and indicate the legal ground that will be used.
Task 2:
**Embedded exercise: select whether the data is anonymous, pseudonymous or directly identifiable. (10 examples)
Data storage
This chapter will discuss the storage options available to researchers at the VU, highlighting their benefits and limitations. Before selecting a storage solution, it's helpful to first gain an understanding of the types of data assets you will be working with, as this will make the decision process much clearer.
Storage is something we encounter daily, whether it's photos on our phone, tax records, or old boxes tucked away in the shed. The way we store these items can greatly affect our ability to find and retrieve them safely when needed.
For example, you wouldn't store an expensive sports car in the same place as an old tractor, as you'd be concerned about damage or theft. Similarly, you wouldn’t park a bus in a private car space, as it simply wouldn’t fit.
The same logic applies to research data. The nature of your data will guide you in selecting the most appropriate storage option. Consider factors such as the sensitivity of your data, its volume, and how you plan to interact with it once it is stored. These considerations will help you choose the right solution for your research needs.

Storage considerations
ChatGPT said:There are various storage options available to VU researchers, each with its own set of benefits and limitations. When deciding where to store your research data, it's important to first assess your specific requirements and use this evaluation to make an informed decision. This section will highlight the key factors that influence storage selection, while the following section will align these factors with the available options, helping you choose the most suitable solution for your research needs.
ChatGPT said:There are various storage options available to VU researchers, each with its own set of benefits and limitations. When deciding where to store your research data, it's important to first assess your specific requirements and use this evaluation to make an informed decision. This section will highlight the key factors that influence storage selection, while the following section will align these factors with the available options, helping you choose the most suitable solution for your research needs.
ChatGPT said:
Data Quantity
- Depending on the kind of data you work with, storage capacity can be an influencing factor on your decision. This refers to the file size and number of files you will produce throughout your research. This is particularly applicable if you work with data such as EEG, MRI, FMRI, video files or high resolution imaging. Over 500GB of data can be classified as a large quantity of data.
Data Sensitivity
- Regulation and policies for handling sensitive (personal) data require specific conditions for data storage. If working with personal data, it is useful to consider the vulnerability of the population and the identifiability of the information which is collected, the higher these are, the higher sensitivity your data is. Features such as restricted access, two factor authentication, and encryption increase the suitability of the storage location.
Data Sharing
- If you are working with organizations outside of the VU, not all options will be suitable. It is important to consider who you will be working with and whether they need access to the data. Collaboration does not always require that all parties have to access to all of the data, so considering the level of access will also help determine where to store your data (e.g. at the folder and sub-folder level).
If you are working with students, limited data access should be implemented so they can only view data files which are necessary for their work.
Physical or Digital Data
- Data comes in a variety of formats. As we move towards digitisation, we see an increased focus on the digital data we produce during research, however when working with data which is physical such as paper questionnaires, informed consent, physical samples, etc. you should also plan a storage location which is suitable for physical data.
The above factors are discussed with requirements in mind, but it is also important to consider what requirements are not necessary. For example, if your data is non-sensitive & non-personal, you should not add security measurements which are not necessary.
Storage options
Yoda
Benefits:
- Approved for high privacy/ confidentiality risks
- Storage of large volumes of data that don't need to be frequently accessed for processing/ analyzing
- Creation of structured metadata to describe your research data (FAIR)
- Access possible for external users (2FA)
- Cost covered by faculty up to 500GB
- Archiving and data publishing available through YODA
- Links with PURE
Limitations:
- Data will likely need to be copied locally prior to data processing/ analysis
- Lacks desktop sync
- Does not allow for access management at a folder and sub-folder level; everyone in the YODA group has access to all folders and sub-folders
Research Drive
Benefits:
- Approved for high privacy/ confidentiality risks
- Storage of large volumes of data that need to be regularly accessed for processing/ analyzing
- Similar to SurfDrive, but works on a project level rather than individual
- Has a desktop sync client for easy management of locally copied data
- Facilitates access management at the folder and sub-folder level
- Access possible for external users
- Cost covered up to 500GB
Limitations:
- Required encryption for very high risk data
- Requires syncing of data locally before processing/ analyzing
- Does not offer structured metadata
- Not suitable for archiving or publishing
SciStor

Benefits:
- Storage of very large volumes of data that need to be regularly accessed for processing/ analyzing
- Data can be accessed directly from SciStor without copying locally
- Best option for high-processing computing
- Allows for access management at the folder and sub-folder level
Limitations:
- Access not possible for external (non-VU) users
- Storage costs not covered up to 500GB
- Additional measures required for very-high risk data
- Access rights managed entirely by IT for Research, changes can only be made upon request
- Not suitable for archiving or publishing
Sharepoint

Benefits:
- Replacement for the previously used G-Drive (and in suitable cases SurfDrive)
- Similar to OneDrive, but ensures data storage is linked to a project rather than an individual
- Allows for access management at a folder and sub-folder level
- Access possible for external users
Limitations:
-
Requires encryption for high risk data
-
Very easy to grant access to data, meaning unauthorised data access can happen by mistake
-
Difficult to maintain an overview of who has access to folders and Teams channels
- Does not offer structured metadata
- Not suitable for archiving or publishing
Summary
Before selecting a storage location for your research data, you must first identify the key requirements for your project and data. This chapter has introduced important factors to consider when defining these requirements, along with an overview of the most common storage options available at VU. However, in some cases, a project may fall outside the scope of these standard requirements, and the existing storage options may not offer the necessary features. If this applies to your project, you should contact the data support staff to discuss your needs and determine whether a custom solution is required.
Don't forget: If you use a key file to store the link between identifiable information and the associated key file, this should be stored in a separate location to the remainder of your research data. This increases the security of your data and reduces the risk of unauthorised re-identification of participants if your research data is compromised.
Task 1:
- Identify Your Requirements: Consider factors such as data sensitivity, security, accessibility, storage capacity, and collaboration needs.
- Review Available Storage Options: Explore the standard storage solutions provided by VU and compare them against your requirements.
- Assess Compatibility: Ensure the chosen storage option meets compliance, backup, and quantity needs.
- Seek Guidance if Needed: If your project has unique requirements that existing options don’t meet, consult the data support staff for advice on a custom solution.
- Make Your Selection: Choose the most suitable storage option and set up your data management plan accordingly.
Task 2:
*embedded exercise on data storage at the VU, match the features with the storage options.
Metadata and documentation
In research, the value of your data extends beyond its initial collection and analysis, it also lies in how well it is documented and described for future use. This is where metadata and documentation play a crucial role. Metadata refers to the structured and unstructured information that describes, explains, or locates your data, providing context and making it easier to discover, interpret, and reuse. Proper documentation, on the other hand, includes detailed explanations about the data’s creation, structure, and how it should be handled or analysed.
Together, metadata and documentation ensure that your research data remains comprehensible and accessible over time, even by individuals who were not involved in its original collection. In this chapter, we will explore the importance of metadata and documentation in research, best practices for creating them, and how they contribute to data integrity, sharing, and long-term preservation. Whether you are working with datasets, surveys, or experimental results, understanding how to effectively document your research is essential for maintaining transparency and ensuring the reproducibility of your work.
Metadata
Metadata is essential for managing and understanding research data, but it can take different forms depending on how it is organised and used. Structured metadata refers to data that is organized in a defined, consistent format, often within a specific schema or database. This allows for easy searchability, categorization, and integration across different platforms.
Unstructured metadata consists of more flexible, free-form information that doesn’t follow a specific format. This could include descriptions, notes, or other contextual information that provides valuable insights but may not fit neatly into a standardized framework. While unstructured metadata may require more effort to manage and analyse, it often captures nuances and details that structured metadata cannot.
In this section, we will explore the differences between structured and unstructured metadata, how they are used in research, and the strengths and limitations of each. Understanding these two types of metadata will help you choose the right approach for documenting and managing your data, ensuring it remains accessible and meaningful for future use.
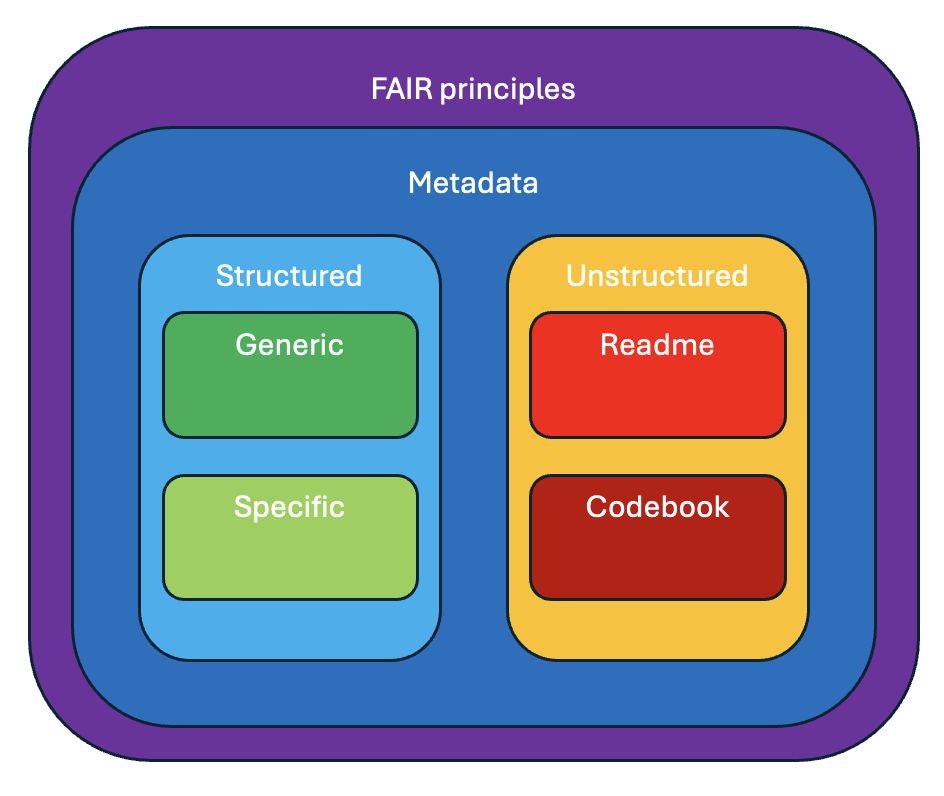
Documentation
Effective documentation is a cornerstone of successful research. It ensures that your data, methods, and findings are clearly understood, reproducible, and accessible to others. Documentation includes not only detailed descriptions of your research process, but also explanations of how data was collected, processed, and analysed. It provides context, outlines any assumptions, and clarifies decisions made throughout the project.
Well-structured documentation helps future researchers, collaborators, or even yourself revisit your work, making it easier to interpret and build upon. In this section, we will explore the key components of research documentation, best practices for creating it, and how good documentation contributes to the transparency, reproducibility, and longevity of your research. Whether you’re managing experimental data, field notes, or analytical methods, proper documentation is essential for ensuring your work remains valuable and understandable over time.
Summary
This chapter highlights the importance of metadata and documentation in research data management. Metadata provides structured or unstructured information that describes, explains, and contextualises your data, making it easier to find, understand, and reuse. Structured metadata follows a predefined format or schema, allowing for better organisation and easier retrieval, while unstructured metadata offers more flexible, free-form descriptions, capturing additional context and nuances.
Documentation plays an equally crucial role by ensuring that the processes behind data collection, analysis, and interpretation are clearly explained and reproducible. It includes detailed descriptions of research methods, assumptions, and any decisions made throughout the project. Good documentation enhances transparency, allows others to understand and reproduce your work, and ensures that your research remains accessible and valuable over time.
Together, metadata and documentation are vital for ensuring the integrity, accessibility, and long-term usability of your research data, facilitating collaboration and enabling future researchers to build upon your work.
Archiving
Closing your project
Closing Summary
Additional information resources
-
Colophon
The arrangement Introduction to Research Data Management is made with Wikiwijs of Kennisnet. Wikiwijs is an educational platform where you can find, create and share learning materials.
- Author
- Last modified
- 07-05-2025 14:24:42
- License
-


This learning material is published under the Creative Commons Attribution 4.0 International license. This means that, as long as you give attribution, you are free to:
- Share - copy and redistribute the material in any medium or format
- Adapt - remix, transform, and build upon the material
- for any purpose, including commercial purposes.
More information about the CC Naamsvermelding 4.0 Internationale licentie.
Additional information about this learning material
The following additional information is available about this learning material:
- Description
- Introduction to Research Data Management Audience: Students Level: introduction
- End user
- leerling/student
- Difficulty
- gemiddeld
Sources
Source Type Research Data Management at the VU
https://www.youtube.com/watch?v=Dw_bwegR76IVideo -
