


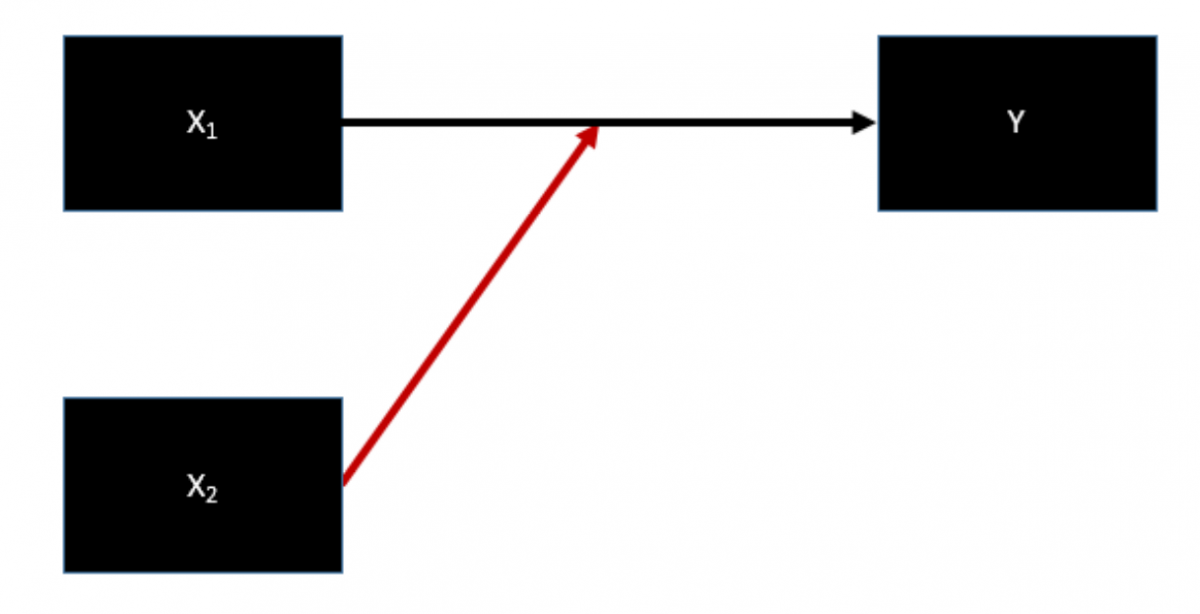
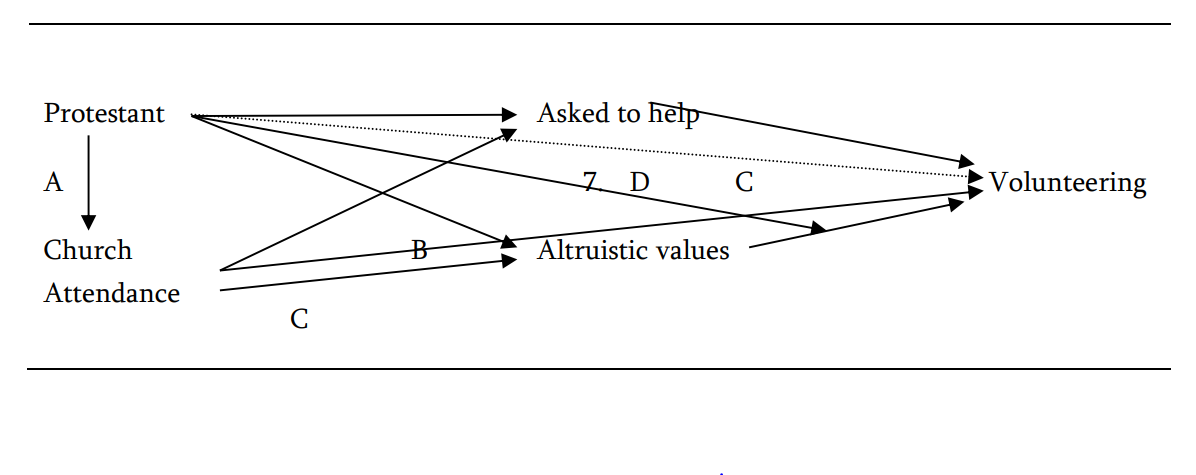
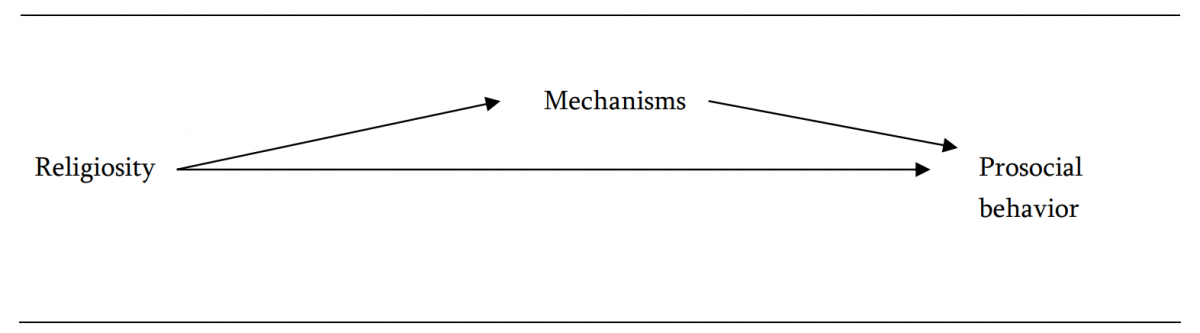
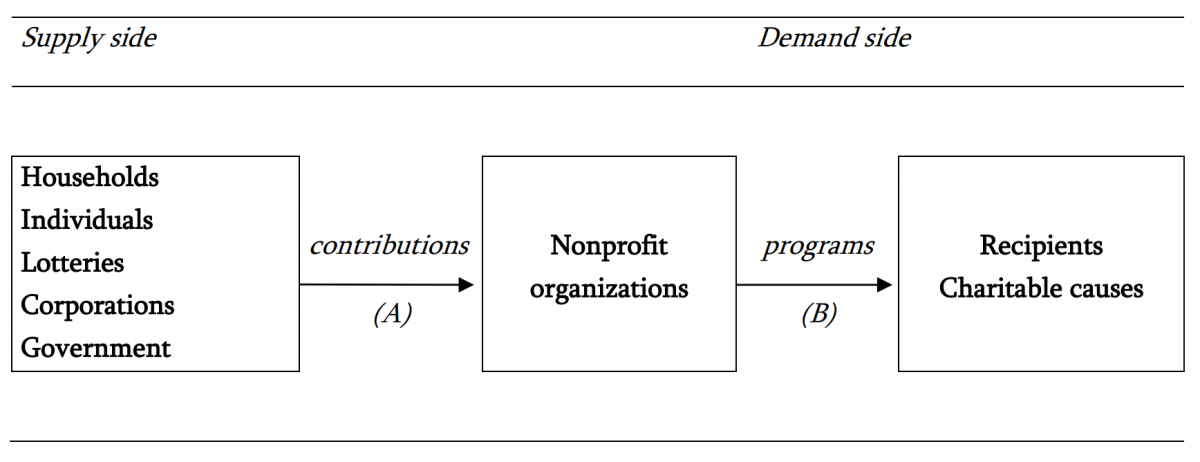






{kind=link}
Het arrangement Better Academic Research Writing: A Practical Guide is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 29-08-2021 13:23:52
- Licentie
-


Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding 4.0 Internationale licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding 4.0 Internationale licentie.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
- A pratical guide for better academic research writing, written by René Bekkers.
- Leerniveau
- WO - Bachelor; WO - Master;
- Leerinhoud en doelen
- Organisatiekunde; Vrijetijdsmanagement; Onderwijskunde; Psychologie; Milieuwetenschappen; Demografie; Aardwetenschappen; Communicatiewetenschap; Huishoudkunde; Sociologie; Economie; Culturele antropologie; Geneeskunde; Sociale geografie; Muziekwetenschap; Documentaire informatievoorziening; Pedagogiek; Bedrijfskunde; Taal- en literatuurwetenschap; Politicologie; Geografie; Bestuurskunde; Sociale wetenschappen; Andragologie;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Trefwoorden
- bachelor thesis, dissertation, master thesis, paper, research