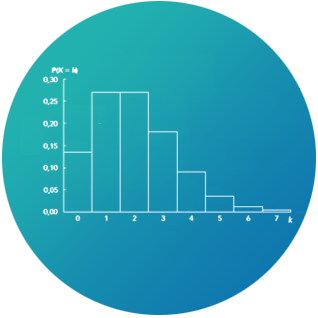
 Je gaat in dit hoofdstuk leren hoe je kansen kunt uitrekenen.
Je gaat in dit hoofdstuk leren hoe je kansen kunt uitrekenen.








 Eindtoets over het thema; in principe de zelftoets.
Eindtoets over het thema; in principe de zelftoets. Je ziet hier twee Extra oefeningen. Je hoeft er maar één te doen.
Je ziet hier twee Extra oefeningen. Je hoeft er maar één te doen.Het arrangement Thema: Verdelingen - 4V Wiskunde A/C is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 2022-01-02 16:26:43
- Licentie
-



Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding-GelijkDelen 4.0 Internationale licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding en publicatie onder dezelfde licentie vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding-GelijkDelen 4.0 Internationale licentie.
Dit thema is ontwikkeld door auteurs en medewerkers van de Wageningse Methode.
Fair Use
In de Stercollecties van VO-content wordt gebruik gemaakt van beeld- en filmmateriaal dat beschikbaar is op internet. Bij het gebruik zijn we uitgegaan van fair use. Meer informatie: Fair use
Mocht u vragen/opmerkingen hebben, neem dan contact op via de helpdesk VO-content.
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Toelichting
- Rearrangeerbare opdracht wiskunde stercollectie VO-content wiskunde havo/vwo
- Leerniveau
- VWO 4;
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Trefwoorden
- leerlijn, rearrangeerbare, vo-content
Gebruikte Wikiwijs Arrangementen
Wiskunde Wageningse Methode OUD. (z.d.).
Thema: Verdelingen - 4V Wiskunde A/C (2.0)
https://maken.wikiwijs.nl/183090/Thema__Verdelingen___4V_Wiskunde_A_C__2_0_