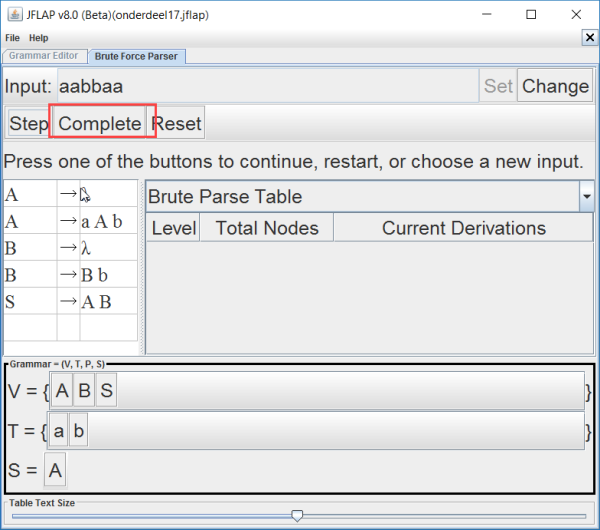


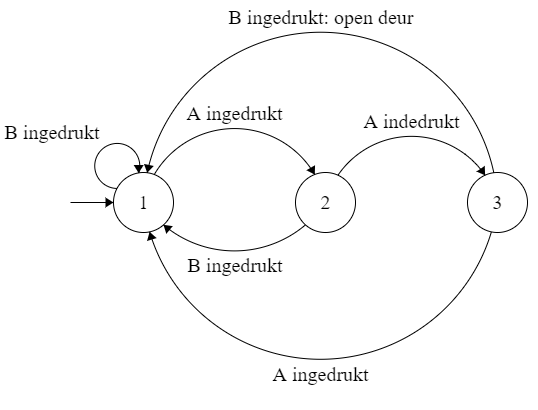
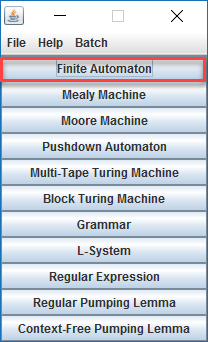
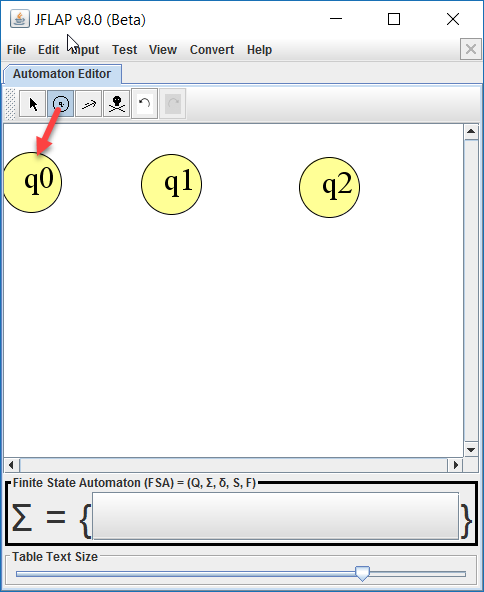
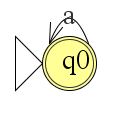
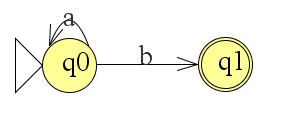
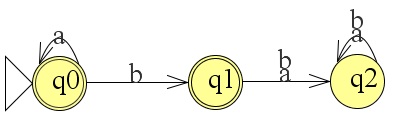
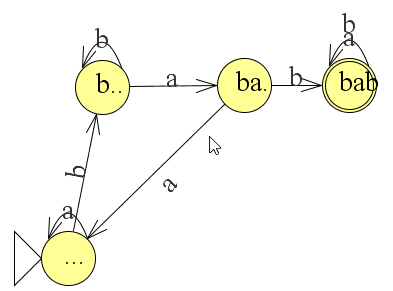
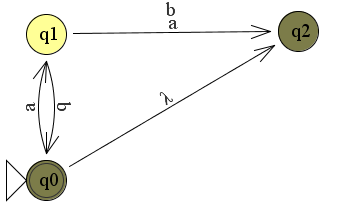
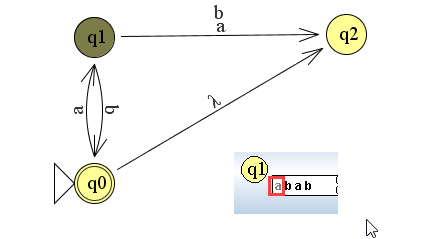
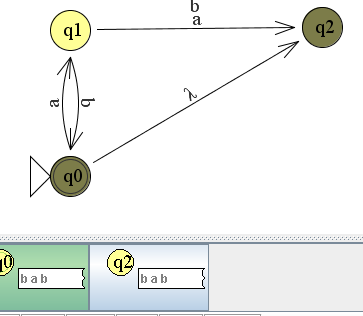
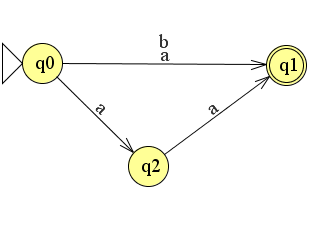
Het arrangement Module: Automaten is gemaakt met Wikiwijs van Kennisnet. Wikiwijs is hét onderwijsplatform waar je leermiddelen zoekt, maakt en deelt.
- Auteur
- Laatst gewijzigd
- 2023-06-20 10:31:20
- Licentie
-


Dit lesmateriaal is gepubliceerd onder de Creative Commons Naamsvermelding 4.0 Internationale licentie. Dit houdt in dat je onder de voorwaarde van naamsvermelding vrij bent om:
- het werk te delen - te kopiëren, te verspreiden en door te geven via elk medium of bestandsformaat
- het werk te bewerken - te remixen, te veranderen en afgeleide werken te maken
- voor alle doeleinden, inclusief commerciële doeleinden.
Meer informatie over de CC Naamsvermelding 4.0 Internationale licentie.
De informatie in deze module is hoodfzakelijk afkomstig van: https://computational.nl/lesson/automaten/1
Aanvullende informatie over dit lesmateriaal
Van dit lesmateriaal is de volgende aanvullende informatie beschikbaar:
- Eindgebruiker
- leerling/student
- Moeilijkheidsgraad
- gemiddeld
- Studiebelasting
- 4 uur 0 minuten